Grundlagen der Betriebsysteme
Bietet eine Einführung in das Thema der Betriebsysteme - untermalt mit Codebespielen und vielen Grafiken.
Kapitel 1 - Einleitung Betriebsysteme
Einleitung - BS Definition
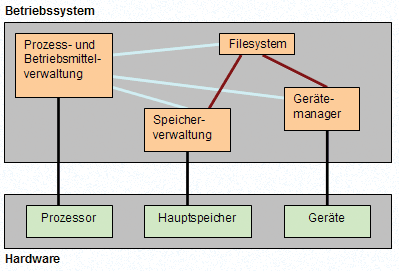
Ein Betriebsystem stellt Dienste und Infrastrukturen (Metasteuerungen) bereit. Daten oder Virtuelle Maschinen sind kein Teil des Betriebssystems sondern des Dienstleistungssystems. Die Metasteuerungen sind entscheidend beim Entwurf. (z.B. in Bezug auf Uni- oder Mehrbenutzersystem)
Grob gesagt ist ein Betriebssystem eine erweiterte Maschine (Top-Down-Sicht), um durch Abstraktionen eine für den Menschen (Programmierer) überschaubare Form als Programmiergrundlage zu bieten.
Eine Definition für Betriebsysteme
Das Betriebssystem ist die Gesamtheit der Programme eines Rechensystems, welche die Betriebssteuerung erledigen und die Benutzeraufträgen eine zugängliche Umgebung bereitstellen. Betriebsmittel sind Komponenten sowohl der Hardware als auch der Software (System und Anwendersoftware), wie z.B. Prozessor, Speicher, Ein-Ausgabe-Geräte, Dateien, Programme etc.
Das Betriebssystem ermöglicht es z.B. dem Anwender, Programme auf unterschiedlicher Hardware laufen zu lassen. D.h. das Betriebssystem bietet dem Anwender eine virtuelle Maschine, welche die reale Hardware "unsichtbar" für den Programmierer macht.
Definition Betriebssysteme
Abstrahiert den Rechner auf eine für Menschen leichter durchschaubare virtuelle Maschine, steuert und koordiniert Prozessabläufe und verwaltet die RessourcenWie sieht das Ebenen- oder Schichtenmodell eines Rechners aus?
- Gatter Ebene
- Mikroprogrammebene
- konventionelle Maschinenebene
- Betriebssystemebene API
- Assemblerebene
- Anwendungsebene
Worin Unterscheiden sich Betriebssysteme?
- universal oder dezidiert (Multi-Task / Single-Task)
- eine oder mehrere Sitzungen (Windows < XP, Linux)
- Kommunikation mit der Umwelt (Batch, interaktiv oder in Echtzeit)
Die dreei Welten des Betriebsystems
- Betriebssystem selbst
- Komplexe Werkzeuge, wie aufgesetzte Dienste oder Virtuelle Maschinen
- Programmiersysteme zur Entwicklung von Erweiterungen
Aufgaben eines Betriebsystems
- Abstraktion der Hardware, d.h. Schließen der so genannten 'Semantischen Lücke' zwischen Mikroprogrammebene und der Anwendungsebene
- Betriebsmittelverwaltung
- Steuerung von Peripheriegeräten (I/O, Festplatten...)
- Steuerung des Betriebsablaufs durch Prozessverwaltung und -Kommunikation und Organisation des Mehrprogrammbetriebes
- Protokollierung, Schutz und Sicherheit
- Behandlung von Ausnahmesituationen, wie Page Faults, Division by Zero u.s.w.
- Bereitstellung einer Kommandosprache
- Unterstützung von Administrationsaufgaben (Datensicherung, Systemkonfigurierung, Benutzerrechte)
Was ist ein Modell?
Ein Modell eines Rechnersystems ist eine Abbildung eines realen Systems unter Abstrahierung bestimmter Kriterien, in dem eine formale Beschreibung durch eine Theorie in Gesetzen formuliert werden kann.
Welche drei Punkte sind bei der Realisierung eines BS grundlegend?
Prozessor-Modes (Betriebszustände)
|
Supervisor Mode (Kernel Mode) |
Ist ein privilegierter Modus für Betriebssystemfunktionen im Kern des Systems, welches Sicherheit des Systems erhöht, da diese geschützt von Andwenderprogrammen laufen. |
|
User Mode (Anwendungsmodus) |
Die Betriebsart wird über ein "Mode"-Bit angezeigt. Privilegierte Funktionen (wie I/O Funktionen) sind aber nur im Kernelmode ausführbar. Diese können über bestimmte Methoden gerufen werden. |
Kernel
Im Kern laufen die Systemkritischen Funktionen, wie z.B. I/O-Aktionen ab. Der Kern muss korrekt, sicher und geschützt vor Anwendungen sein.
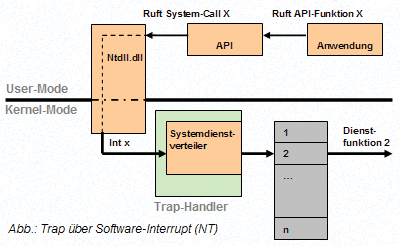
Methoden des Aufrufs von Betriebssystemsdiensten
| System Calls | Durch System Calls können BS-Funktionen gerufen werden. Die Schnittstelle zwischen Usermode und Kernel sind sogenannte Traps (Einstiegspunkte). Geräte können Traps nicht nutzen, sondern können die BS-Dienste durch spezielle Interruptsmechanismen erreichen. |
| Nachrichtenversand | Über eine Send/Receive-Schnittstelle können sich User-Mode und Kernel-Mode Nachrichten zuschicken. |
Sinn und zweck ist eine Entkopplung von System und Anwendung! Windows NT bietet
eine API mit mehr als 10.000 Systemaufrufen, Unix dagegen ca. 300.
Kapitel 2 - Modelle
Vor- und Nachteile von Schalen- und Modulmodellen
Das Schalenmodell
- Relationen der einzelnen Schalen sind zur Umwelt nicht sichtbar
- System ist aber gut strukturiert
- Innere Schalen sind sehr gut abgeschirmt von den Äußeren
Das Modulmodell:
- Das Modell wird in Modulen durch Programmcode beschrieben
- die Relationen werden daher extrem komplex (quatradisch)
- Daher ist es nur bei kleinen Modellen umsetzbar
Aufbau des hierarchischen Schichtenmodells
Jede Schicht stellt Betriebsmittel und Dienste für den Zugriff auf die jeweilige übergeordnete Schicht bereit. Somit kann jede Schicht auch die Betriebsmittel und Dienste darunterliegender Schichten nutzen. Eine Schicht steuert die unmittelbare Schicht über ihr. (Steuerungshierarchie)
Bestandteile
- Schichten
- Iterative Ordnungsrelation der Schichten (Dienste, Steuerungen bzw. Instanzen)
- Betriebsmittel
- Funktionen zum Erzeugen von Betriebsmitteln und Steuerungen
Welche Vorteile hat das hierarchisch Schichtenmodell?
- obwohl modularisiert, ist die Zahl der Relationen gering
- Kommunikation mit der Umwelt ist möglich
- Es bietet eine Infrastruktur für Instanzen (Steuerung, BM-Transformationen)
Was ist ein Betriebsmittel?
Ein Betriebsmittel ist eine abstrakte Ressource, welche über eine Adresse und einen Wert verfügt. Sie wird definiert über
- ID (eindeutiger Identifikator)
- Adressbereich (für alle möglichen Adressen des Betriebsmittels)
- Wertebereicht (aller möglichen Werte für einen Wert des BM)
- Funktion (verknüpft die abstrakten Elemente miteinander)
Welche Klassen von Betriebsmitteln gibt es?
- Entziehbarkeit (entziehbar wie Prozessor oder nicht wie Dateideskriptor)
- Zuteilbarkeit (gleichzeitig wie Speicher oder exklusiv wie Prozessor oder Drucker)
- Wiederverwendbarkeit (einmalig Nutzbar wie Interrupt oder mehrfach wie Prozessor oder Speicher)
- Hardware / Software (logisches oder physikalisches Betriebsmittel)
Vorgehensweise beim Erstellen eines Betriebsmittels
- ID bestimmen
- abstrakte Elemente bestimmen, welche einen Wert und eine Adresse besitzen
- Wert und Adresse festlegen
- Funktionen definieren, welche Zugriff auf alle Elemente ermöglichen
Die Betriebsmittelerstellung am Beispiel des Hauptspeichers
- Eine ID ist hier nicht sinnvoll, da ein von-Neumann Rechner nur einen Hauptspeicher hat.
- die abstrakten Elemente sind die ansprechbaren Speicherzellen mit Adresse und Wert.
- Der Wertebereich beträgt 0 bist 255 bei einem Byte-Orientierten Speicher
- Funktionen sind Read und Write eines Elementes zum Speicher
Definition Instanz
Eine Instanz ist ein Tupel aus id (Betriebsmittel) und einem Aktivitätstoken, welches die einzelnen Dienste ruft. Zwischen Betriebsmitteln untereinander und zwischen Instanzen untereinander bestehen Relationen.
Klassen von Instanzen
- Applikationen
- Betriebsmittel-Transformatoren
- Metasteuerungen wie PUM
Wie können Relationen zwischen Instanzen technisch hergestellt werden?
Protokolle und Schnittstellen verbinden sich Instanzen. Dabei treten beide immer zusammen auf. Eine Schnittstelle kennzeichnet das statische Verhalten einer Relation und ein Protokoll das dynamische, d.h. die Semantik der Relation.
Als Beispiel nehmen wir einen Spooler. Hier ist die Schnittstelle ein Betriebsmittel (Speicherbuffer) und das Protokoll (Verhalten) ist als Dienst implementiert.
Spool = Simultanously Periphal Output On Line
Es gibt datenorientierte und steuerungsorientierte Schnittstellen. Datenorientierte Schnittstellen arbeiten ohne Synchronisation und verbrauchen viel Ressourcen (Busy Waiting). Steurerungsorientierte Schnittstellen sind z.B. Systemcalls und Interrupts.
Kapitel 3 - Aktivitäten
Was ist ein Aktivitätstoken?
- Ist sehr abstrakt zu sehen
- Ein Aktivitätstoken haucht dem Programm erst "Leben" ein
- Beschreibt ein aktiven oder wartenden Prozess
- Es muss eine Art virtuellen Programmcounter im eigenen virtuellen Steuerwerk des Prozesses geben
Definition Multitasking
Ist die Fähigkeit Prozesse parallel laufen zu lassen. Bei Einprozessormaschinen (kooperativ oder preemtiv) wird die Leistungsfähigkeit damit optimal ausgenutzt. Die verschiedenen Betriebsmittel können von mehreren Prozessen mehrfach bzw. parallel genutzt werden.
Arten von Aktivitäten
| Token | Verteilung | Protokoll | BM-Zuteilung | |
|---|---|---|---|---|
| Prozedur | Eins für alle | - | Call Return | Exclusiv |
| Coroutine | Eins für alle | - | Resume, aber dynamischer Eintrittspunkt (kooperatives Multitasking) | Exclusiv |
| Prozess | Pro Prozess | Pro Prozess | Keine Übergabe, da Prozess Token behält | Exclusiv |
| Thread | Pro Prozess | Pro Thread Eins | Keine Übergabe, da Prozess Token behält | Threads sind in Prozessen gruppiert und teilen sich dort die Betriebsmittel |
Welche Betriebsmittel benötigt eine Aktivität mindestens?
- Programmcode
- Hauptspeicher
- Steuerwerk
Wodurch wird ein Prozess beschrieben?
- ein im System eindeutiger Identifikator (PID)
- Liste mit Betriebsmittel-Forderungen
- Liste mit zugeteilten Betriebsmitteln
- Ein Folge der bisherigen Anweisungen
- Die Anfangswertbelegungen der zugeteilten Betriebsmittel
Welche Probleme treten mit Prozessen auf?
- Determiniertheit (Durch Mehrfachverwendung von Betriebsmitteln ist diese so nicht mehr gegeben und Synchronisation wird notwendig)
- Mutual Exclusion
- Synchronisation (Abstimmung zwischen Threads)
- Kommunikation (Synchronisation und Austausch von Daten zwischen Prozessen)
- Lebendigkeit
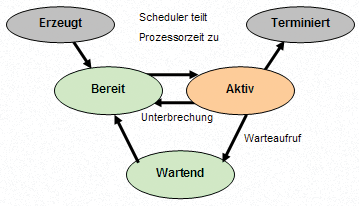
Welche Zustände kann ein Prozess einnehmen?
- nicht existent (Prozess noch nicht definiert)
- bereit (besitzt alle angeforderten Betriebsmittel außer den Prozessor)
- aktiv (besitzt mindestens die angeforderten Betriebsmittel)
- wartend (wartet noch auf noch nicht zugeteilte Betriebsmittel)
Wie wird ein Prozess im Unix erstellt?
- mit Systemaufruf fork() wird ein komplettes Speicherabbild eines schon bestehenden Prozesses erzeugt (bei NT wird Prozess mit einem Initialzustand erstellt)
- Deshalb erben neue Prozesse eventuelle Variablen des Vaterprozesses
Deshalb terminiert folgende Schleife nicht unter NT aber unter Unix:
For ( i=1; i<3; i++) fork();
Einige Unix-Systembefehle zur Prozesserzeugung:
- fork(), vfork() zum Prozesserstellen mit Speicherabbild des Vaters
- clone() erstellt einen Prozess der der den Speicher und Deskriptoren mit Vater teilt
- execl(), execv(), execle(), execlp(), execvp() zum Kopieren eines Programms in den Speicher
- wait(), waitpid() zum Warten auf Ende des Sohnprozesses
- exit() zum Beenden eines Prozesses
Ein Beispielcode für eine Einfache Unix-Shell
#include sys/types.h
#include sys/wait.h
#include unistd.h
#include stdlib.h
#include stdio.h
#include string.h
using namespace std;
int main(void){
pid_t pid; //für PID des Sohnes
char str1[1000]; //Befehlsbuffer
while(1){
printf("\nDiggs mini bash. (PID=%d)\n\n",getpid());
printf("> ");
scanf("%s",str1); //Befehl lesen
if (strcmp(str1,"exit")==0) break; //exit beendet
if ((pid=fork())<0) //Prozess kopieren
{
printf("EXEC Operation failed!\n\n");
exit(0);
}
if (pid==0) //im Sohnprozess exec
{
char *cmd=strtok(str1," ");
execlp (cmd,cmd,0); //Speicher überschreiben
printf("command not found!\n");
exit(0); //manuell terminieren
} //Vaterprozess muss warten
else
waitpid(pid,0,0);
}
return 0;
}
Der Vaterprozess liest einen Befehl (hier nur ohne Parameter) und startet danach einen Sohnprozess mit fork() in welchem mit dem Befehl exec das aufzurufende Programm in den Speicher kopiert wird. Schlägt exec fehl muss mit exit der Sohnprozess manuell beendet werden, da dieser sonst nicht terminieren würde.
Am Besten einfach ausprobieren. Den Quellcode eingeben oder kopieren und mit dem gcc compilieren:
gcc minishell.cc -o minishell
Aufruf in einer bash via ./minishell
Wie werden Prozesse verwaltet?
Das Betriebssystem verwaltet alle Prozesse. Die Prozesse besitzen einen PCB (Process Controll Block, in welchem alle zum Prozess gehörigen Informationen gespeichert werden. Das Betriebssystem hat nun die Aufgabe alle n Prozesse auf einen oder mehr Prozessoren abzubilden.
Timesharing
Timesharing ist die gemeinsame Benutzung des Betriebsmittels Prozessor von mehreren Prozessen. Dabei ermittelt ein Scheduler den nächst auszuführenden Prozess. Ein Task-Switch bzw. Context-Switch bezeichnet eine solche Umschaltung zwischen den Prozessen.
Virtuelle Geräte bzw. Betriebsmittel?
Virtuelle Geräte stellen durch das Betriebssystem simulierte Geräte mit idealisierten Eigenschaften dar. Bewerkstelligt wird damit die Abstraktion von den Eigenschaften realer Geräte mit dem Ziel der Geräteunabhängigkeit. In der Regel stellen virtuelle Geräte jedem Prozeß eine synchrone Operation zur Verfügung. Dabei kann es erheblich mehr virtuelle als reale Geräte geben. Beispiele für virtuelle Betriebsmittel sind Druckerspooler oder Dateien.
Kapitel 4 - Kritischer Abschnitt
Definition
Ein Kritischer Abschnitt ist ein zeitlicher Bereich, in welchem mindestens zwei Prozesse auf das gleiche Betriebsmittel zugreifen und mindestens eines davon schreibt. (Zeitkritischer Ablauf)
Der Druckerspooler als Beispiel einer Critical Section
- in Spooler ist der Platz 4 frei
- Prozess A will drucken und liest die Platznummer
- PUM aktiviert Prozess B, welcher ebenfalls diese Platznummer liest
- Prozess B schreibt den Auftrag nach Platz 4
- PUM schaltet zu A zurück und A überschreibt nun den Druckauftrag von B!
Warum werden keine Interrupt Unterbrechungen zur Synchronisation verwendet?
Ein Prozeß der auf gemeinsame Daten und Ressourcen zugreift, kann nicht einfach alle Interrupts abschalten. Dies würde zu keinem optimalen Scheduling führen, weil dann jeder Prozeß solange die Kontrolle behalten darf wie er will. D.h. die wartenden Prozesse sind auf die Kooperation des gerade laufenden Prozesses angewiesen (kooperatives Multitasking wie Win 3.11)
Was ist wechselseitiger Ausschluss?
Es muss gewährleistet werden, daß niemals sich mehr als ein Prozess in einem kritischen Abschnitt befinden darf. Die Anwendung einer einfachen Sperrvariable ist hier nicht möglich, da der Zugriff und das Setzen dieser, selbst einen kritischen Abschnitt darstellt. Es müssen Algorithmen gefunden werden, welche die Funktionalität gefahrlos implementieren.
Welche Anforderungen muss eine Steuerung für kritische Abschnitte erfüllen?
- exklusive Nutzung durch verschiedene Teilprozesse über mutual exclusion
- Ein Prozess darf einen anderen nur behindern, wenn beide im kritischen Abschnitt
- Der Eintritt in einen kritischen Abschnitt darf nicht lang dauern
- Alle Prozesse müssen in endlicher Zeit ihre Betriebsmittel zugewiesen bekommen
- globale Unabhängigkeit von allgemeinen Fortschreiten der Prozesse
Arten dezentraler Steuerungen (aktives Warten)
- Test and Set Lock
- Ping-Pong (Striktes Alternieren)
- Decker Algorithmus
- Peterson Algorithmus
Striktes Alternieren (Ping Pong)
| Prozess A | Prozess B |
While (1)
{
while (turn!=FALSE);
criticalsection();
turn = TRUE;
notcriticalstuff();
}
|
While (1)
{
while (turn!=TRUE);
criticalsection();
turn = FALSE;
notcriticalstuff();
}
|
| Hier wird nur mit einer TURN Variable zwischen den Prozessen hin und her geschalten. Nachteil ist das die Abläufe nur abwechselnd in die kritischen Abschnitte eintreten können und das ein nicht im kritischen Abschnitt arbeitender Prozess trotzdem warten muss, bis der andere diesen wieder verlassen hat. | |
Der Peterson Algorithmus
CONST N = 2; //konkurrierende Prozesse
INT turn; //Container für aktiven Prozess
INT interested[N];
void P(int process) //Eintreten
{
int other = 1-process; //Gegenteil des Prozesses
interested[process] = TRUE; //Interesse bekunden
turn = process; //Flag setzen
while(( turn==process ) AND (interested[other]==TRUE));
}
void V(int process) //Welcher Prozess verläßt K.A.
{
interested[process]= FALSE; //Kein Interesse mehr
}
Das turn erzwingt ein Warten des interessierten Prozesses, solange ein andere Prozess im K.A. ist. Der Hauptnachteil von dezentralen Steuerungen für kritische Abschnitte ist das Aktive Warten (Spin Locks), was bedeutet, dass die Blockierzeit anderer Prozesse nicht genutzt werden kann.
Semaphore - zentrale Steuerung
Ein Semaphor ist ein allgemeiner Mechanismus zur Synchronisation, ohne aktiv warten zu müssen. Das Verfahren wurde von Dijkstra (1965) entwickelt und hat sich durchgesetzt. Ein Semaphor arbeitet auf einer priviligierten Schicht des Betriebssystems und ist somit nicht Teil der Prozesse.
Ein Binärer Semaphor kann einen Kritischen Abschnitt für zwei Prozesse verwalten. Falls mehrere Prozesse gleichzeitig auf ein Betriebsmittel zugreifen dürfen, reicht der binäre Semaphor nich aus. Der Semaphor wird dann als Zähler implementiert. Falls er 0 ist, ist das Betriebsmittel voll ausgelastet. Ist er größer als 0, so sind noch Ressourcen vorhanden, d.h. andere Prozesse dürfen in den Kritischen Abschnitt eintreten, solange der Semaphor nicht Null ist. Dabei dekrementieren sie diesen und blockieren ihn für andere Prozesse, falls der Semaphor nun Null ist. Verläßt ein Prozess den Kritischen Abschnitt, inkrementiert der Prozess den Semaphor wieder und signalisiert damit, dass er seine Arbeit getan hat und nun ein anderer eintreten darf. Daher werden die beiden Operationen vor und nach dem Kritischen Abschnitt oft als Down(sem) und Up(sem) definiert.
Das Grundprinzip von Semaphoren
Es wird nicht mehr eine Art Sperrvariable verwendet, sondern ein Zähler. Für dieses Zähler gibt es die Operationen up(s) bzw. V und down(s) bzw. P zum Erhöhen bzw. Dekrementieren des Zählers. Ist nach einem down(s) der Zähler null, wird gewartet. Ist er irgendwann wieder größer als null werden die Anweisungen ausgeführt. Der Semaphor ist nun nichts weiter als dieser Zähler, welcher nur durch up und down ansprechbar ist! Die beiden Operationen P und V stellen natürlich auch kleine kritische Abschnitte dar, welche über aktives Warten synchronisiert werden.
P(sem) //Probiere in kritischen Abschnitt einzutreten
{
if (sem == 0)
sleep(sem); //Prozess auf wartend setzen
sem--;
}
V(sem) //Verlasse kritischen Abschnitt
{
sem++; //Zugang wieder freigeben
wakeup(sem);
}
sleep und wakup sind Systembefehle, welche einen Prozess Schlafenlegen oder Aufwecken.
| Prozess A | Prozess B |
int sem = 1; //zwei Prozesse |
|
While (1)
{
P(sem);
// kritischer Abschnitt
V(sem);
}
|
While (1)
{
P(sem);
// kritischer Abschnitt
V(sem);
}
|
Events
Betriebssysteme wie z.B. Unix benutzen Events als Abstraktion von Semaphoren zum Koordinieren von Prozessabläufen (im Gegensatz zu kritischen Abschnitten). Ein Ereignis stellt nichts weiter als eine für Software erkennbare Bedingung dar. Ein Prozess kann sich Schlafen legen, bis eine bestimmte Bedingung eintreten.
- Ein Prozess setzt einen wait()-Aufruf auf ein Ereignis ab. Er wird dann an dem Event-Deskriptor wartend gesetzt.
- Wenn an dem Event-Deskriptor das Ereignis signalisiert wird, so wird ein dort wartender Prozess bereit gesetzt.
- Der wesentliche Unterschied zu den Semaphor-Operationen ergibt sich daraus, dass die Signale nicht gespeichert werden, bei Semaphoren wird dagegen der Wert bei signal() um 1 erhöht.
Semaphore
Wert 0. Kommt das signal() vor dem wait(): der wait()-aufrufende Prozess wird nicht blockiert.
Event
Ein Wert ist nicht vorhanden, kein Prozess wartet. Das Ereignis wird vor dem wait()-Aufruf signalisiert: der wait()-aufrufende Prozess wird blockiert, bis ein weiteres Ereignis eintrifft. Das erste Ereignis wird nicht gemerkt.
Monitor
Ein Monitor besteht aus einigen Prozeduren, Variablen und Datenstrukturen die zu einer besonderen Art Modul zusammengefasst werden. Dieses Monitormodul verkapselt Semaphore und die Operationen auf diesen Semaphoren. Nützlichste Eigenschaft eines Monitors ist, daß jeweils nur ein Prozeß zu einer Zeit einen Monitor benutzen kann. Ein Monitor ist zwar vielen Prozessen zugänglich, aber nur jeweils ein Prozeß kann den Monitor zu einem gegebenen Zeitpunkt benutzen. Monitore werden häufig zur Verwaltung von Puffern und Geräten eingesetzt.
Synchronisationsmöglichkeiten
- Es gibt dezentrale und zentrale Steuerungen für kritische Abschnitte
- Dezentrale Steuerungen ist das aktives Warten
- Zentrale Steuerungen sind Semaphore (passives Warten)
- Beim passiven Warten werden Prozesse schlafengelegt
- Ereignisse dienen der Koordination
Was ist das Erzeuger-Verbraucher-Problem?
Zwei Prozesse nutzen einen Puffer mit N Plätzen zum Datenaustausch. Während Prozess A Daten sequentiell in den Puffer schreibt, entnimmt Prozess B ein Datum aus dem Puffer.
Nun stellen sich die Fragen
- Wie soll man das gleichzeitige Einfügen und Entnehmen synchronisieren?
- Ein Datum darf nur eingefügt werden wenn der Puffer nicht voll ist.
- Ein Datum darf nur eingefügt werden, wenn noch Platz im Buffer ist.
- Ein Semaphor für die Kontrolle des kritischen Abschnittes
- Ein Semaphor, welcher die freien Plätze zählt
- Ein Semaphor, welcher die vergebenen Plätze zählt
const N 100 //buffer size
int mutex = 1 //Für Kritischen Abschnitt
int empty = N //Anfangs leerer Buffer
int full = 0 //noch keine Daten im Buffer
void ErzeugerProzess()
{
int item;
while(1)
{
iNode = CreateItem();
P(empty);
P(mutex);
Insert(item) //Critical Section
V(mutex); //Mutex wieder erhöhen
V(full); //full=full+1
}
}
void VerbraucherProzess()
{
int item;
while(1)
{
P(full);
P(mutex);
Item = RemoveItem(); //Critical Section
V(mutex);
V(empty);
MakeSomething(Item);
}
}
Der Semaphor mutex verhindert, daß gleichzeitig Verbraucher und Erzeuger im kritischen Abschnitt sind. Denn falls der Erzeuger gerade eingetreten ist, ist der Semaphore mutex null. Versucht nun der Verbraucher in den kritischen Abschnitt einzutreten, muss er bei P(mutex) warten, da der mutex noch null ist. Um nun zu Verhindern das aus einer leeren Liste gelesen oder in eine volle geschrieben wird, werden hier elegant zwei weitere Semaphoren verwendet, welche das Vorhandensein von freien Plätzen (empty) und belegten P lätzen (full) zählen.
Das Philosophenproblem
Beim Philosophenproblem geht es nicht um Kommunikation sondern um Synchronisation. Abstrakt gesehen, gibt es N Prozesse und N Betriebsmittel. Ein Prozess benötigt mindestens zwei der Betriebsmittel um fortschreiten zu können. Ohne Synchronisation, würden im schlimmsten Fall alle 5 Prozesse je ein Betriebsmittel bekommen und dann unendlich darauf warten, daß ein anderer Prozess eins freigibt.
Es sitzen fünf Personen an einem runden Tisch. Sie können entweder Denken oder Essen. Es gibt zwar für jeden einen Teller, aber nur fünf Stäbchen. Um Essen zu können braucht man aber bekanntermaßen zwei.
Wie kann das Philosophenproblem gelöst werden?
Natürlich denkt man zuerst an Semaphoren. Nur funktioniert die triviale Lösung mit einem Semaphor pro Stäbchen nicht. Es können immer noch alle Philosophen je ein Stäbchen gleichzeitig aufnehmen und die Prozesse wären allesamt verklemmt. Es muss also irgendwie möglich sein, mehr als ein Stäbchen gleichzeitig aufzunehmen. Bei den verschiedenen Implementationen ist vor allem darauf zu achten, daß dieses Aufnehmen der beiden Stäbe eine Atomare Funktion ist.
Unix-Signale
Ein Ereignis wird hier als Signal bezeichnet. Unter Unix gibt es vorgegebene durchnummerierte Signale. Unter Unix kann mit kill(Prozessnummer, Signalnummer) einem Prozess ein Ereignis signalisiert werden.
Die Reaktion eines Prozesses auf ein Signal kann verschieden ausfallen:
- Aktivierung einer Prozessfunktion, die der Prozess vorher für dieses Signal mit der Funktion signal( Signalnummer, Funktionsadresse) angemeldet hat
- Er kann das Signal mit signal(Signalnummer, SIG_IGN); ignorieren
- Der Prozess kann beendet werden.
- Hat der Prozess für eine Signalnummer nichts festgelegt, dann gibt es Voreinstellungen:
| #define SIGFPE | 8 | /* Floating point trap */ | |
| #define SIGILL | 4 | /* Illegal instruction */ | |
| #define SIGINT | 2 | /* voreingestelle Interrupttaste z.B. Ctl -c*/ | |
| #define SIGSEGV | 11 | /* Memory access violation */ | |
| #define SIGTERM | 15 | /* Kill -Kommando ohne Angabe*/ | |
| #define SIGKILL | 9 | /* unbedingter Prozessabbruch*/ |
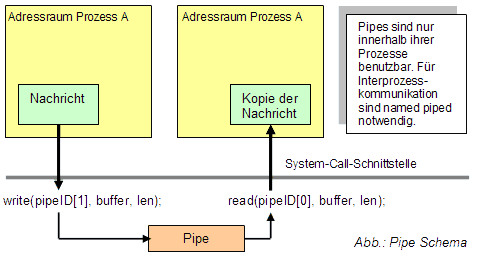
Was unterscheidet Pipes und Named Pipes?
Pipes sind nur innerhalb von Prozessgruppen (UNIX) oder zwischen Threads eines Prozesses verwendbar, da diese nur dort bekannt ist (und eindeutig identifizierbar). Diese Einschränkung kann mit der Named Pipe umgangen werden. Eine Named Pipe ist ein mit einem eindeutigen Namen versehenes Objekt des Betriebssystems. Ein Prozess kann die Pipe erstellen, ein anderer kann eine Verbindung zu der Pipe herstellen. Im UNIX erhält eine Named Pipe einen Pfadnamen, wie eine Datei.
Sockets
Sockets sind im Grunde Pipe-Erweiterungen für Internet und andere Netzdienste. Dabei werden ein Socket A und ein Socket B zu einer bidirektionalen Pipe verbunden. Identifiziert wird ein Socket über Rechneradresse und Portnummer. So ermöglichen Sie eine Client-Server-Kommunikation:
Ein Serverprozess erstellt einen Socket mit create und wartet dann auf Verbindungswünsche (listen).
Möglichkeiten zur Kommunikation und Synchronistation
Kommunikation
- Pipes (FIFO-Puffer - Senden (Schreiben) ist asynchron, Empfangen (Lesen) blockierend)
- Named Pipes
- Mailboxen (Tool zum Senden und Empfangen von Nachrichten)
- Send - Receive (BS Unterstützung für Mailboxen - synchron oder asynchron)
- Queues
- Sockets
- RPC
- Shared Memory
Synchronisation
- Monitore
- Events
- Semaphore
- Barierren (oft zur Threadsynchronisation verwendet)
Kapitel 5 - Scheduling
Scheduling wird notwendig, wenn die Anzahl der gleichzeitig laufenden Prozesse die Anzahl der physikalischen Prozessoren übersteigt. Die Verwaltung kann dezentral (Prozesse selbst) oder zentral erfolgen. Es gibt zwei grundlegende Modelle für zentrale Scheduling-Verwaltung:
- Deterministisches Modell - alle Informationen bekannt (Anzahl Prozesse/Betriebsmittel/Zeitdauer)
- Probabilistisches Modell - offen (Anzahl Prozesse nicht bekannt) oder geschlossen (Anzahl Prozesse bekannt, aber Bedienzeiten nicht)
Strategien zur Prozessorzuteilung
- Durchsatz (Anzahl bearbeiteter Prozesse pro Zeiteinheit maximieren)
- Verweilzeit (Prozess soll so schnell wie möglich abgearbeitet sein)
- Wartezeit (Dauer im Zustand "wartend" minimieren)
- Effizienz (Prozessorleistung maximal ausnutzen)
- Antwortzeit (möglichst kurze Reaktionszeiten für den Benutzer)
- Fairness (gerechte Verteilung der Prozessorzeit)
Es ist nicht möglich CPU-Auslastung und Durchsatz zu maximieren und gleichzeitig Warte- und Antwortzeit zu minimieren. Deshalb müssen alle Scheduling Algorithmen Kompromisse eingehen.
Nach welchen Kriterium richtet sich das Scheduling Verfahren?
Dies hängt in erster Linie vom Einsatzgebiet des Systems ab:
- Echzeitbetrieb
- Dialogbetrieb
- Stabel- bzw. Batchbetrieb
- Hintergrundbetrieb
Das deterministische Scheduling-Modell
Bei diesem Modell werden die Schedules vor der Ausführung berechnet. Dies funktioniert natürlich nicht in interaktiven offenen Systemen, sondern nur in geschlossenen Systemen mit fester Prozessanahl und vordefinierter Betriebsmittelnutzung mit statischen Ablauf. In Dialogsystemen wird deshalb das offene probabilistische System verwendet, da hier Anzahl der Prozesse und Betriebsmittelnutzung dynamisch erfolgen...
Das probabilistisches Scheduling-Modell?
Die Entscheidung welcher Prozess den Prozessor bekommt, wird dynamisch wärend der Prozessabarbeitung gefällt. Hierbei gibt es einige wichtige Größen, welche als stochastische Variablen zur Berechnung herangezogen werden können. Die Warteschlangentheorie ist wichtiges Mittel für Untersuchungen. (Alle Prozesse welche den Prozessor fordern werden in eine Warteschlange eingereiht).
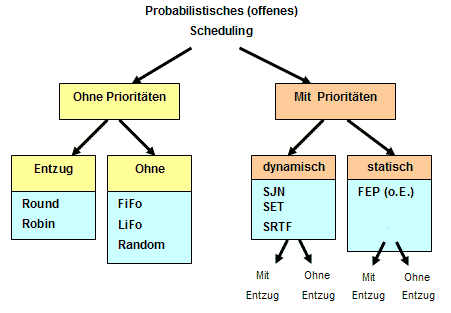
Die Abbildung entspricht einem Scheduling ohne Prioritäten und ohne Entzug.
Das Single-Server-Modell
Eine Warteschlange nimmt Prozesse in einem bestimmten Abstand (A) auf. Der Scheduler entnimmt nach einer gewissen Wartezeit (W) im Pool einen Prozess und führt diesen in einer bestimmten Zeit (B) aus .
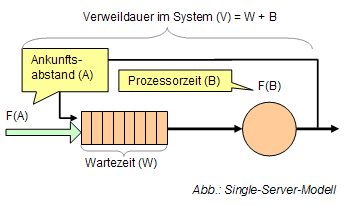
| mittlere Verweildauer in Warteschlange | W |
| Zwischenankunftsabstand | A |
| Prozessorzeit der Teilprozesse | B |
| Anzahl von Prozessen in Warteschlange | Nq (N=Nq+p) |
| Verkehrswert | p=B/A (Poisson-Prozesse) |
| Verweildauer im System | V=A*N (Littles Theroem) |
Weiter Größen wie durchschnittliche Warteschlangellänge oder die Wahrscheinlichkeit das sich n Prozesse im System befinden, lassen sich mit Poissen-Verteilungen genauso wie die oben erwähnte mittlere Verweildauer ermitteln.
Wahrscheinlichkeiten für Prozessgrößen
Durch Poisson-Prozesse (Markow) können Erwartungswerte, Mittelwerte und Varianzen für Zwischenankunftsabstände, Bedienwünsche und Auslastung berechnet werden. Die Betrachtungen beziehen sich hier auf den stationären Fall (t->unendlich, also FiFo).
First Come First Serve - FCFS
Ankommende Prozesse werden in eine FIFO Liste eingereiht und sequentiell abgearbeitet. Somit ist dieses Modell nicht für Timesharing geeignet, da es eher eine Batchverarbeitung ist.
Kommt ein langer Prozess zuerst, müssen andere winzige Prozesse alle auf die Beendigung des großen Prozesses warten! Unfair. Bessere Implementationen können deshalb das Token entziehen.
Durchschnittliche Wartezeit W = (Wartezeit(P1) + Wartezeit(P2) + ... + Wartezeit(Pn)) / n
Ist P1 ein vielfach größerer Prozess als die restlichen, so müssen alle folgenden Prozesse auf die Beendigung von P1 warten. Dies läßt die durchschnittliche Wartezeit extrem steigen.
Bsp.:
t(P1) = 24 t(P2) = 3 t(P3) = 3
Bei einer Abarbeitungsfolge von P1 -> P2 -> P3 wäre W = 17. Bei einer Abarbeitungsfolge von P2 -> P3 -> P1 nur 3!
Was ist Prioritäts-Scheduling?
Hier wird jedem Prozess eine Priorität zugewiesen. Ausgewählt wird vom Scheduler der ausführbereite Prozess mit der höchsten Priorität. Die Prioritäten können statisch definiert und dynamisch zugewiesen werden.
Bsp: FEP (Fixed ExternalPriorities)
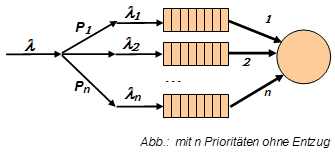
Das Grundproblem von Schedulern mit Prioritäten
Hauptproblem beim Arbeiten mit Prioritäten ist das Aushungern von Prozessen, welche möglicherweise nie aktiv werden können, da es immer Prozesse höherer Priorität gibt.
Lösung hierfür ist das Aging. (dynamische Anhebung der Priorität der älter werdenden Prozesse)
Ein anderes Problem ist die Prioritätenumkehr. Ein hochpriorisierter Prozess wartet auf ein Betriebsmittel, welches ein niedrigpriorisierter Prozess reserviert hat.
Shortest Job First (dynamische Priorität ohne Entzug)
Es wird der kürzeste Job zur Verarbeitung ausgewählt. Dabei werden die Durchlauflängen der einzelnen Prozesse protokolliert. Nach jedem Prozesswechsel wird die "bereit"-Warteschlange anhand der Wartezeiten absteigend neu sortiert.
Deshalb optimiert Shortest Job First die mittlere Wartezeit. Problem ist hier auch das Aushungern von Prozessen, was auch durch Aging (Altern) verhindert werden kann.
SJF ist ohne Entzug (nonpreemtiv). Eine Variante mit Enzug ist SRTF. Dabei wird der Prozessor entzogen, falls ein Prozess in der Warteschlange ist, der kürzer als der verbliebene Rest des aktiven Prozesses.
Wie arbeiten Shortest Remaining Time First und Shortest Elapsed Time (dynamisch mit Entzug)?
Diese beiden Verfahren sind mit Prioritäten und mit Entzug. Sie sind daher relativ aufwendig, da ein ständiger Abgleich der Prioritätsdaten erfolgen muss. Bei SET wird Prozessen, welche schon viel Prozessorzeit zugesprochen bekamen, die die Prozessorzeit entzogen.
Highest Response Ratio Next - HRN
Umso länger ein Prozess wartet, umso höher steigt er in seiner Priorität. So wird Aushungern verhindert.Round-Robin Scheduling (ohne Prioritäten)
Das RR ist die verbreitetste Strategie, da sie fair ist und sich auch einfach implementieren lässt. Das Prinzip ist einfach. Jeder Prozess erhält für eine konstante Zeit t (Quantum) die Prozessorzeit. Nach Ablauf des Zeitquantums wird der nächste Prozess aus der Warteschlange entnommen und bearbeitet. Der zuvor bearbeitete Prozess wird wieder am Anfang der Liste eingefügt.
Hauptproblem ist eine sinnvolle Zeitspanne für das Quantum zu finden. Da bei jedem Kontextwechsel Register umgeladen müssen, muss ein gewisser Zeitraum für Verwaltungsarbeiten eingerechnet werden. Dauert das Umladen der Register 5 ms macht ein Quantum von 10 ms wenig sinn, da 50% Prozessorzeit verschwendet werden würde.
Wählt man das Quantum aber zu groß (z.B. 500 ms) so ist im Mehrbenutzerbetrieb nur bedingte Interaktivität möglich. (RR nähert sich somit FCFS an) Sinnvoll erwiesen sich Quanten von 100 ms.
Scheduling Algorithmen
- Scheduling mit oder ohne Entzug
- Scheduling mit oder ohne Prioritäten
Zweistufiges Scheduling
Angenommen der Arbeitsspeicher reicht nicht aus, um alle Prozesse abzubilden, müssen diese auf einen Tertiärspeicher ausgelagert werden. Da das Auslagern bzw. Einlagern eines Prozesses sehr viel Zeit in Anspruch nimmt, werden zwei Stufen benutzt, um das Scheduling zu realisieren. Die erste Stufe arbeitet nur im Hauptspeicher, während die zweite Stufe für das Ein- oder Auslagern von Prozessen verantwortlich ist. Kriterien sind hier dieselben wie oben schon erwähnt.
- Wie lange ist ein Prozess Aus- oder Eingelagert?
- Wieviel Prozessorzeit hat ein Prozess in Anspruch genommen?
- Wie groß ist der Prozess im Speicher?
- Welche Priorität hat der Prozess?
Was steht im Widerspruch zu hohem Durchsatz und guter Auslastung?
Im Widerspruch dazu stehen gutes Antwortzeitverhalten im Dialog- und Stapelbetrieb. Denn ein hoher Durchsatz und eine gute Auslastung bedingen viele Prozesse im Rechner, so daß jeder Prozeß nur relativ selten aktiv werden kann, d.h. das Antwortzeitverhalten schlechter wird. Auch die Zuteilungsfairness wird dadurch zunehmend schlechter bzw. unfairer.
Kapitel 6 - Speichermanagment
Übersicht zur Freispeicherverwaltung
Es gibt drei grundlegende Ansätze zur Verwaltung des freien Speichers. Diese werden im folgendem Text erläutert.
Bitmaps?
Bitmaps teilen den Hauptspeicher in gleich große Einheiten und assoziieren zu jedem Eintrag ein Bit in der Bitmap. Ist der Eintrag 0, so ist der Speicherbereich noch frei. Bei Nutzung eines Speicherbereiches wird in dem assoziierenden Bitmapplatz eine eins platziert. Umso kleiner die zusammengefassten Einheiten werden, umso größer wird die Bitmap. Der größte Nachteil von Bitmaps ist das Suchen von freien Speicherbereichen, was eine aufwendige Operation darstellt.
Suche in Freispeicherlisten
Bei dieser Variante werden Listen für Löcher und belegte Segmente durch Prozesse geführt.
| First Fit | Der erste freie Block der groß genug ist wird ausgewählt, egal wieviel Speicher dadurch verschwendet wird (interne Fragmentierung). |
|---|---|
| Next Fit | Suche beginnt nicht vom Anfang der Liste, sondern vom zuletzt verwendeten Listenelement. |
| Best Fit | Es wird der optimale Platz in Bezug auf Speicherausnutzung gesucht. Dadurch das immer Blöcke mit der geringsten Speicherplatzverschwendung gesucht werden, werden die freien Blöcke irgendwann zu klein. |
| Quick Fit | Es gibt mehrere Listen für verschiedene Blockgrößen. |
Wie funktionieren Buddy Listen?
Listen haben den Nachteil, daß benachbarte freie oder belegte Speicherbereiche sich nicht zusammenlegen lassen. Abhilfe schafft hier das Buddy-System. Die Idee beruht darauf, dass mehrere Listen geführt werden, welche aber nur Blockgrößen von 2^n zulassen. Zweierpotenz deshalb, weil ein Rechner Binärzahlen zur Adressierung benutzt.
Beispiel
Die maximale Blockgröße beträgt 64 Mbytes und die minimale Blockgröße 4 Kbyte. D.h. 226 - 212, also müssen Listen für N=12 bis N=26 verwaltet werden. Somit wären für diese Blockgrößenwahl mit dem Buddysystem 15 Listen notwendig.
Anfragen werden nun immer zur nächsthöhren Zweierpotenz aufgerundet. D.h. wird eine Anfrage an einen 75 Kbyte Block gestellt, muss ein 128 Kbyte großer Slot verwendet werden. Anfangs gibt es eine Liste für in unserem Beispiel 64 Mbyte Speicher. Der Buddymanager würde die Liste rekursiv so oft teilen, bis ein 128 Kbyte großer Block in eine der anderen Listen frei ist.
Falls die angeforderten Blockgrößen aussschliesslich Zweierpotenzen wären, würde es zu keiner Internen Fragmentierung kommen können. Da dies aber nie der Fall ist, wird viel Speicher durch interne Fragmentierung verschwendet.
Zusammenfassung Freispeicherverwaltung
Bitmaps unterteilen den Speicher in Allokationseinheiten. Für jede Einheit gibt es ein Bit im Bitmap. Verknüpfte Listen bieten Suchmöglichkeiten mit First Fit, Best Fit oder Quick Fit. Quick Fit setzt mehrere Listen bestimmter Lochgößen voraus. Das Buddy System verwaltet n Listen von 1,2, 4, 8 bis zur Größe des Speichers. D.h. ein 1 MByte großer Speicher benötigt 21 Listen und hat Initial nur einen einzigen Eintrag in der letzten Liste, der das 1 MByte große Loch beschreibt. Alle anderen Listen sind leer. Speicher wird nun immer in Abhängigkeit von einer Potenz von 2 vergeben, der gerade noch groß genug ist, um die Daten aufzunehmen. Dies wird einfach implementiert, in dem der Große block einfach solange geteilt wird, bis der Datenblock in den Freispeicherblock passt. Das Buddysystem ist zwar schnell, aber impliziert eine starke interne Fragmentation, da ja immer auf Zweierpotenzen gerundet werden muss.
Methoden zur Freispeicherverwaltung
- einfache verkettete Listen mit Best-,Next- oder First-Fit Suche
- Bitmap-System welches Speicher in gleichgroße Einheiten teilt
- Buddy-Listen nach dem binären System
Segmentierung (mehrdimensionale Adressräume)
Eindimensionale Adressierung hat den Nachteil, daß Programme mit verschieden dynamisch wachsenden Programmteilen nur schlecht realisierbar sind. Code, Stack und Daten würden hintereinander im Speicher liegen. Benötigt ein Programm aber extrem viele Variablen, würde der Compiler mit der Fehlermeldung abbrechen, daß es nicht genug Speicher gäbe. Um nun mehrere Stack, Daten und Codebereiche getrennt voneinander adressieren zu können, ohne daß die verschiedenen Teile in Konflikt geraten, wurden die Segmente eingeführt.
Segmentierte Speicherung wird oft als das Prinzip der gestreuten Speicherung benannt. Gestreut deshalb, weil die einzelnen Seiten nicht nacheinander im Speicher liegen müssen, sondern dort eingefügt werden, wo Platz ist. Anders als z.B. bei Kontinuierlicher Allokation, wo viel Speicher durch externe Fragmentierung verlorengeht, tritt bei Segmentation dieses Problem nicht auf. Dafür aber interne Fragmentierung...Wie werden Segmenten adressiert?
Um mit Segmenten arbeiten zu können, sind zweiteilige Adressen notwendig, bestehend aus Segment und Offset. Die Segmentation muss also dem Programmierer bewusst sein, da ein Segment nur eine logische Einheit darstellt. Besonders einfach gestaltet sich das übersetzen von Prozeduren. Angenommen jede Prozedur hat ihr eigenes Codesegment, benötigt man nur die Segmentnummer, um die Funktion aufzurufen, da der Eintrittspunkt bei der logischen Adresse 0 dieses Segmentes ist.
Wird nun eine Prozedur neu kompiliert, müssen die restlichen Prozeduren nicht neu kompiliert werden, da der Eintrittspunkt immer noch der gleiche ist. Und zwar 0. Die Segmentnummern werden eh dynamisch vergeben.
Gemeinsam genutzte Segmente
Durch Segmentierung wird es sehr einfach, verschiedene Codesegmente gemeinsam zu nutzen. So genannte Shared Libraries sind in jedem modernen Betriebssystem notwendig, denn sie stellen für viele Programme Frameworks oder API's bereit, deren Funktionalität sich jedes Programm bedienen kann, soweit es die dafür notwendigen Zugriffsrechte hat. Ob ein Segment ausführbar ist oder nicht, wird über die Schutzart des Segmentes definiert.
Das Prinzip des virtuellen Speichers durch Paging
Um mehr Speicher bereitzustellen werden statt echter physikalischer Adressen virtuelle benutzt, welche durch die MMU in reale Adressen bei Benutzung umgewandelt werden. Durch das Paging können Seiten aus- oder eingelagert (nach einem Page Fault) werden. Eine Page Table referenziert virtuelle auf physikalische Adressen. Swapping ist in Reinform sehr langsam. Sinnvollerweise werden Segmente in Seiten geteilt, welche durch Paging ein oder ausgelagert werden. (Protected Mode) Die MMU kann, muss aber nicht auf der CPU liegen. Jede Seitentabelleneintrag hat ein Present/Absent Bit, welches Auskunft darüber gibt, ob eine Seite sich im Speicher befindet oder nicht. Des Weiteren vermerkt eine Art Dirty Bit, ob eine Seite im Speicher geändert wurde, um entscheiden zu können, ob ein zurück schreiben notwendig wird.
Die momentan verwendeten Seiten eines Programmablaufes wird Working Set genannt. Demand Paging bedeutet, dass Seiten erst dann abgefordert werden, wenn sie benötigt werden.
Eine virtuelle Adresse besteht aus Seitenummer und Offset. Bei einem Contextswitch wird nach der entsprechenden Seitennummer in der Page Table gesucht und die zugehörige physikalische Adresse errechnet. Es wird meist ein n-stufiges Paging angewandt, um die Suche mach den Seiten zu beschleunigen (Unix) . Bei i386 gibt es ein so genanntes Seitenverzeichnis (DIR) mit 1024 Zeilen, welche wiederum je auf eine Seitentabelle verweisen. Somit enthält eine lineare Adresse beim Intel DIR,PAGE und OFFSET Teil. (mehrstufiges Paging)
Beim Swapping werden statt Seiten ganze Prozesse ausgelagert.
Virtual Memory und Caching
- Demand Paging und Caching basieren auf den gleichen Prinzip
- Sie arbeiten nur auf verschiedenen Ebenen
- Cache-Misses werden von der Hardware geregelt, Page Faults vom Betriebssystem
Der TLB - Translation Lookaside Buffer
Um die Zeit der Adressumrechnung zu vermindern, wird in der MMU ein Assoziativspeicher mit meist nicht mehr als 32 Einträgen verwaltet. Die Einträge enthalten die zuletzt verwendeten virtuellen Seiten mit der dazugehörigen Seitenrahmennummer im Speicher. Gleichzeitig wird dort vermerkt, welche Art von Lese/Schreibzugriff erlaubt ist und ob die Seite verändert wurde. Kommt eine Anforderung auf eine nicht im TLB vorhandene Seite, wird ein Eintrag aus dem TLB mit der neu dekodierten Adresse überschrieben, so daß bei der nächsten Anfrage die Adressumrechnung entfallen kann.
Translation Lookaside Buffer
- TLB's werden verwendet, wenn Seitentabelle auf Grund eines zu großen Adressraumes nicht möglich ist
- TLB bildet zuletzt genutzten (64 bei UltraSparc) virtuellen Seitennummern auf physikalische Seitenrahmen ab
- häufig benutzte Seiten werden in einem Cache (Translation Storage Buffer) verwaltet
- Dieser Cache bildet Seiten direkt ab und wird bei TLB-Miss zuerst untersucht
- befindet sich die Seite nicht im Cache, muss sie in der Translation Table gesucht werden
Invertierte Page Tables?
Eine Seitentabelle enthält hier einen Eintrag für jeden Seitenrahmen des physikalischen Speichers. Der Eintrag enthält Informationen über den besitzenden Prozess und die virtuelle Seite. So entspricht die Anzahl der Einträge der Anzahl der Seitenrahmen im Speicher. Die Tabelle verwaltet nur, welche Seite, von welchem Prozess in den Seitenrahmen des Arbeitsspeicher geladen wurden.
Paging Dämons
Paging arbeitet nur effizient, wenn jederzeit genügend Seitenrahmen im Speicher frei sind, um diese bei einem Page Fault neuen Seiten belegen zu können. Doch wie wird sichergestellt, daß der Speicher komplett ausgefüllt werden muss und somit bei einem Page Fault erst eine Seite ausgelagert werden muss? Viele Betriebssysteme haben dafür einen speziellen Dienst vorgesehen. Der Paging Dämon wird in zyklischen Abständen aktiviert. Dieser schaut nun nach ob genügend Frames im Speicher zur Verfügung stehen. Ist dies nicht der Fall, werden so viele Seiten wie notwendig mit einem der Seitenersetzungsalgorithmen aus dem Speicher entfernt und auf die Platte zurückgeschrieben.
Das Zusammenspiel von Segmentierung und Paging
Um beide Vorteile (Mehrdimensionalität und virtuellen Speicher) nutzen zu können, werden in fast allen modernen Betriebssystemen beide Techniken angewandt. Dabei wird das Paging transparent, also für den Programmierer nicht sichtbar, hinter die Segmentierung geschalten. Auf dieser Basis bauen sich auch die Adressen dieser Maschinen auf. Es gibt verschiedene Implementationen von Segmentierung und Paging. Aber letztendlich haben sie eines gemeinsam. Die logische Adresse besteht aus
- die Segmentnummer zur Auswahl des richtigen Segmentdeskriptors und
- den Offset zur Adressierung innerhalb des Segmentes.
Die Implementierungen unterscheiden sich nun in der Verwaltung der Deskriptoren und der Art und Weise wie die aus Segment + Offset entstandene virtuelle Adresse über die Page Table auf den realen Speicher projiziert bzw. umgerechnet wird.
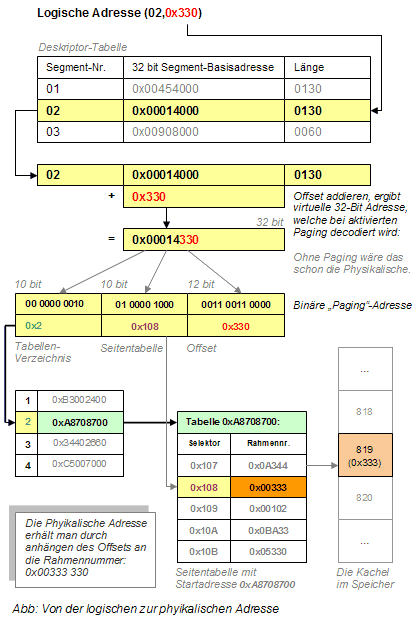
Was passiert wenn Sie ein Programm starten?
- Der Virtual Memory Manager verwaltet den virtuellen Speicher.
- Bei Programmstart richtet das BS für den Prozess eine Seitentabelle ein.
- Eine definierte Anzahl Rahmen werden dem Prozess als Arbeitsmenge zugeteilt.
- Seiten aus dem Read-Only Bereich der EXE werden direkt geladen und brauchen nicht zurückgeschrieben werden.
- Read-Write Bereiche werden zuerst direkt aus der EXE geladen und im Speicher hinterlegt.
- Bei einem Schreib-Bezug wird sie als private Kopie in die Auslagerungsdatei geschrieben. So können mehrere Prozesse die selbe EXE im benutzen. (Copy On Write)
- freie Seiten, welche mit 0 initialisiert wurden (zerofilled)
- uninitialisierte freie Seiten, die noch alten Inhalt haben
- wartende Seiten, die Prozess zugewiesen waren und nicht modifiziert wurden(standby pages)
- wartende, aber modifizierte Seiten (modified pages)
- belegte Seiten, welchen einem Prozess zugewiesen / referenziert sind (valid pages)
- unbenutzbare Seiten, durch z.B. Hardwarefehler (unusable pages)
Adressumrechnung der Multics
- mit Segmentnummer wird Segmentdeskriptor festgestellt
- es wird geprüft, ob die Pagetable des Segmentes im Speicher ist
- ist sie nicht im Speicher tritt ein Segmentfehler auf und es erfolgt ein Trap
- ist sie im Speicher wird der Pagetableeintrag für die angefragte Seite überprüft
- falls Seite nicht im Speicher entsteht Page Fault
- ist Seite im Speicher wird die physikalische Adresse des Seitenursprungs aus dem Pagetableeintrag entnommen
- Der Offset wird zur gewonnenen Adresse hinzuaddiert und die physikalische Adresse ist berechnet.
(nach Tanenbaum)
Meist wird ein Assoziativspeicher verwendet, um die letzten paar Umrechnungen ohne Verzögerung ausgeben zu können. Ein TLB enthält zwei Vergleichsfelder für Segmentnummer und korrespondierende virtuelle Seite und einige zusätzliche Attribute, wie Schutzattribute, Age oder Referenziert-Bits.
Adressumrechnung beim Pentium 2
Intel Prozessoren besitzen ab dem i386 eine LDT (local descriptor table) und eine GDT (global descriptor table). Die Local Descriptor Tables enthalten die programmeigenen Segmente, wie Stack-, Code- und Datensegment der verschiedenen Benutzerprogramme. Die Global Descriptor Table enthält dagegen die Systemsegmente samt deren des Betriebssystems , welche erst geladen werden muss. Wird ein Segmentselektor in ein Segmentregister geladen, wird der entsprechende Bezeichner aus der LDT oder GDT geholt und in MMU Registern gespeichert. Ob L- oder GDT kann dem Selektor entnommen werden, da dort ein Bit für diese Auswahl reserviert ist. Der Deskriptor besteht nun aus der Basisadresse des Segmentes, der Größe des Segmentes und verschiedenen Privilegbits. Es wird nun eine virtuelle Adresse über Segmenteselektor + Offset gebildet. Bei deaktiviertem Paging ist nun diese Adresse die lineare physikalische. Ist aber Paging aktiv wird die Adresse als virtuell interpretiert und über die Seitentabelle auf den realen Speicher abgebildet.
Sicherheit und Segmentverwaltung
Jeder Deskriptor in einer Deskriptortabelle ist mehrere Byte breit und enthält Beschreibungsinformationen für ein Segment aus dem linearen Adressraum. Neben der Segment-Basisadresse (BASE) enthält er das LIMIT, das die Segmentgröße angibt. Dabei wird durch ein Granularitätsbit festgelegt, ob das LIMIT direkt als Länge interpretiert wird (Segmentgrößen bis 1 MB) oder mit dem Wert 4096 multipliziert wird und damit Segmentgrößen bis 4 GB unterstützt. Der Descriptor-Privilege-Level gibt an, mit welcher Berechtigungsstufe der Zugriff auf das Segment erfolgen muss:
- Level 0: Betriebssystem
- Level 1, 2: Betriebssystemdienste, Treiber, Systemsoftware
- Level 3: Anwendungssoftware
Weitere Informationen im Deskriptor zeigen an, ob auf das Segment lesend, schreibend oder ausführend zugegriffen werden darf und ob es sich um ein System- oder Anwendungssegment handelt. Ein Present-Bit gibt an, ob das Segment sich derzeit überhaupt im Hauptspeicher befindet.
Zusammenfassung von Freispeicherverwaltung, Segmentierung und Paging
Segmentierung wird genutzt, um statt einen linearen Adressraum (wie beim virtuellen Speicher), mehrere virtuelle Adressräume nutzen zu können. Segmentierung wurde entworfen, um dynamisch wachsende Tabellen besser Handhaben zu können. Somit ist schafft Segmentierung einen mehrdimensionalen Adressraum.
Unter Swapping versteht man das komplette Ein- und Auslagern von Prozessen. Das Swapping des segmentierten Speichers ist vergleichbar mit dem Demand-Paging des virtuellen Speichers. Nur das Segmente unterschiedlich groß sein können. Aus diesem Grund tritt hier das Problem der externen Fragmentierung auf.
Um die externe Fragmentierung zu minimieren, werden die Löcher als verkettete Liste im Speicher gehalten. Falls ein Segment geladen werden soll, sucht z.B. Best Fit, dass nächst größere Loch unter allen, wo das Segment passen würde. First Fit nimmt das Nächste Loch, welches für das Segment groß genug wäre.
Neben dem Swapping kann auch Paging zum Auslagern von Segmenten benutzt werden. Hierbei sind die auszulagernden Blöcke gleich groß, da die Segmente in gleich große Seiten eingeteilt werden. Zur Auslagerung wird das bekannte Demand Paging benutzt. Meist wird eine Kombination aus Segmentierung und Paging angewandt, bei der die Adresse aus zwei Teilen besteht. (Segmentnummer und Offset innerhalb des Segments). Segmente werden also in Seiten unterteilt. Zur Leistungsverbesserung werden die zuletzt verwendeten Segment-Seiten- Kombinationen in einem Assoziativspeicher (TLB) gehalten. Im Gegensatz zum Paging ist es beim reinen Swapping nicht möglich, Prozesse auszuführen, die alleine schon nicht in den Hauptspeicher passen.
Bitmaps unterteilen den Speicher in Allokationseinheiten. Für jede Einheit gibt es ein Bit im Bitmap. Verknüpfte Listen bieten Suchmöglichkeiten mit First Fit, Best Fit oder Quick Fit. Quick Fit setzt mehrere Listen bestimmter Lochgößen voraus. Das Buddy System verwaltet n Listen von 1,2, 4, 8 bis zur Größe des Speichers. D.h. ein 1 MByte großer Speicher benötigt 21 Listen und hat Initial nur einen einzigen Eintrag in der letzten Liste, der das 1 MByte große Loch beschreibt. Alle anderen Listen sind leer. Speicher wird nun immer in Abhängigkeit von einer Potenz von 2 vergeben, der gerade noch groß genug ist, um die Daten aufzunehmen. Dies wird einfach implementiert, in dem der Große block einfach solange geteilt wird, bis der Datenblock in den Freispeicherblock passt. Das Buddysystem ist zwar schnell, aber impliziert eine starke interne Fragmentation, da ja immer auf Zweierpotenzen gerundet werden muss.
Kapitel 7 - Seitenersetzung
Seitenersetzungsalgorithmen
Falls eine Seite angefordert wird, aber kein Platz für deren Einlagerung im Speicher mehr vorhanden ist, so muss eine andere Seite entfernt werden. Aber welche? Es gibt nun verschiedene Ansätze für dieses Problem...
Welcher wäre der beste Algorithmus zur Seitenersetzung?
Dieser ist theoretisch gegeben, aber nicht umsetzbar. Die Seite die am spätesten erst wieder verwendet wird, wird ausgelagert. Da in einem Echtzeitsystem nie vorhersagbar ist, welcher Prozess wann wie lange aktiv sein wird, ist diese Strategie nicht umsetzbar... In einem deterministischen Modell wäre er aber durchaus denkbar, da dort jeder Schritt eindeutig definiert ist.
Seitenersetzung mit Not-Recently-Used - NRU
Jede Seite bekommt zwei Statusbits zugeordnet. R wird gesetzt, wenn die Seite lesend oder schreibend referenziert wurde. M wird gesetzt, falls die Seite verändert wird. Diese beiden Bits sind in jedem Seitentabelleneintrag enthalten und müssen bei jeder Seitenreferenzierung aktualisiert werden.
Die zwei Bit stellen vier Klassen dar, welche genutzt werden um einen Paging-Algorithmus zu realisieren.
- nicht referenzierte und nicht modifizierte Seite
- nicht referenzierte und modifizierte Seite
- referenzierte und nicht modifizierte Seite
- referenzierte und modifizierte Seite
LRU wählt zufällig eine Seite aus der kleinstnummerierten Klasse zum Entfernen aus.
Seitenersetzung mit Fifo - First In First Out
Es wird eine Liste geführt, welche alle Seiten enthält. Neue Seiten werden an das Ende der Liste angefügt. So ist die Liste nach dem Alter der Seiten sortiert. Der FiFo Paging-Algorithmus macht nichts weiter, als bei einem Seitenfehler die älteste Seite zu entfernen, also die Seite, die am Anfang der Liste steht.
Das Problem an Fifo ist, daß auch extrem häufig referenzierte Seiten ausgelagert werden. Um dies zu umgehen wird das oben schon erwähnte R (Referenziert) Bit verwendet, um jeder Seite eine zweite Chance zu geben, falls das R-Bit nicht null ist.
Seitenersetzung mit Second Chance
Arbeitet wie Fifo, nur wird beim Entfernen des Kopfes nachgeschaut, ob das R Bit null ist. Wurde die Seite nie referenziert, so wird sie entfernt, wie für FiFo üblich. Wurde sie aber referenziert, wird sie zum Ende der Liste verschoben, als wurde sie neu geladen. Das R-Bit wird dabei auf Null gesetzt. So wird gewährleistet, das häufig benutzte Seiten weniger oft als nicht referenzierte Seiten ausgelagert werden. Second Chance ist ein durchaus guter Paging Algorithmus mit einem Nachteil. Es müssen ständig konstante Seiten innerhalb der Liste von Anfang zum Ende verschoben werden. Diesen Nachteil bügelt der Uhr Algorithmus aus.
Der Uhr-Seitenersetzungsalgorithmus
Der Clock-Algorithmus arbeitet im Prinzip wie Second Chance, nur das anstelle einer FiFo Liste eine Ringliste verwendet wird. Dabei wird in einem Pointer (Zeiger der Uhr) auf den aktuellen Anfang der Liste gezeigt. Bei einer Second Chance muss nun nicht die Seite verschoben werden, es wird einfach der Zeiger auf das nächste Element referenziert.
Der Uhr Algorithmus ist also eine Implementation von Second Chance mit einer Ringliste.
Seitenersetzung mit Least-Recently-Used - LRU
Dieser Paging Algorithmus versucht den Optimalen zu approximieren, indem es versucht die Seiten zu entfernen, welche am Längsten nicht mehr benutzt wurden.
Die Implementation ist trotzdem nicht ganz einfach. Es müsste theoretisch eine Liste geführt werden, welche nach dem oben genannten Kriterium sortiert ist. Diese Liste müsste nach jeder Seiteneinlagerung neu Sortiert werden. Da dies eine zu komplexe Operation darstellt, muss dafür eine Softwarelösung approximiert werden, welche wesentlich schneller arbeitet.
LRU mit Matrixumsetzung
Es wird eine globale N x N Matrix für alle N Seiten geführt. Diese Matrix wird mit 0 initialisiert. Wird eine Seite x referenziert, so wird die Zeile x auf 1 gesetzt und danach die Spalte x auf 0. In jedem Moment ist die Zeile deren Summe am Kleinsten ist, die am wenigsten genutzte und die Zeile mit dem größten Wert, die am häufigsten genutzte Seite.
Wenn die notwendige Hardware (Matrix) nicht vorhanden ist, muss ein anderer effizienter Paging Algorithmus benutzt werden, der ohne jede Hardware auskommt.
Seitenersetzung NFU - Not Frequently Used
Bei jeder Uhrunterbrechung wird das Referenziert-Bit jeder Seite auf einen Softwarezähler, welcher mit null initialisiert wurde, hinzuaddiert. Es wird also versucht zu zählen, wie oft eine Seite referenziert wird. Das Problem von NFU ist es, dass Spitzen in der Referenzierung starke Auswirkungen auf den Zähler haben. So kann es vorkommen, daß eine Seite, welche anfangs stark genutzt wurde und später nicht mehr, einer zyklisch genutzten Seite nicht zur Auslagerung vorgezogen wird.
Eine Modifikation von NFU versucht LRU zu simulieren und diesen Fehler aufzuheben.
Seitenersetzung mit Aging - LRU durch Softwareemulation
- Vor der Addition es Referenziert-Bits werden alle Zähler um eins nach rechts geschoben
- das Refenziert-Bit wird auf das am weitesten links stehende Bit addiert
Bei einem Seitenfehler wird auch hier die Seite mit dem kleinsten Fehler entfernt. Durch das Rechtsverschieben verkleinert sich der Wert eines Zählers rapide und es wird verhindert, daß nur kurzeitig verwendete Seiten fälschlicherweiße als oft referenziert angesehen werden...
Seitenersetzungsalgorithmen
- Not-Recently-Used (referenziert und modifiziert Bits - vier Zustände)
- Least-Recently-Used (Seiten die lange nicht benutzt worden auslagern) und LRU mit Matrixumsetzung
- FiFo, Second Chance, Uhr-Seitenersetzungsalgorithmus
- Not Frequently Used (über Zähler für Referenzierungen)
- Aging - LRU durch Softwareemulation
Die Belady's Anomalie
Eine Erhöhung der Seitenrahmen im Speicher, also mehr Speicher, heißt nicht zwangsläufig eine Verringerung von Seitenfehlern!
Was passiert beim Einsatz einer schnelleren Platte mit der Seitenfehlerrate?
Die Seitenfehlerrate steigt, da die Übertragungszeit für Seiten sinkt. Die Anzahl der gleichzeitig ausführbaren Prozesse steigt, da jeder Prozeß nun mit weniger Seitenrahmen - und einer höheren Fehlerrate - "leben" kann.
Working Sets - dynamisches Seitenaustauschverfahren
Prozess Arbeitsbereiche werden eingesetzt und die Zahl der Seitenfehler weiter zu minimieren. Ein Prozess unterliegt auch einer Art Lokalität. Es werden im Mittel bestimmte Seiten häufiger und Andere sogut wie nie oder gar nicht zur Prozessabarbeitung benötigt. Man nennt dies Referenzielle Lokalität.
Mit Arbeitsbereichen wird versucht Informationen vor dem Laden eines Prozesses auszunutzen, um häufig verwendete Referenzen bevorzugt zu behandeln. Die Erfassung der für das Working Set notwendigen Daten wird auch über eine Art Aging Algorithmus umgesetzt. Jede Seite gehört zu einem bestimmten Working Set. Wird eine Seite länger als N Ticks nicht mehr benutzt, wird sie aus dem Working Set entfernt.
Die gewonnene Information des Working Sets kann verwendet werden, um den Clock Algorithmus zu verbessern. Und zwar wird nicht nur nach einer nichtreferenzierten Seite geschaut, sondern auch ob die Seite zu einem Working Set gehört oder nicht. Falls sie einem Arbeitsbereich angehört, wird sie übersprungen, egal ob im Moment referenziert oder nicht.
Welche Problematik tritt bei der Arbeitsmengenstrategie auf?
Das Hauptproblem ist die Seitenauslagerung durch Herausfallen von Seiten aus dem Working Set. Seiten können aus dem Working Set ausgelagert werden, ohne das ein Seitenfehler vorliegt und ohne das für diese Seite eine Neue eingelagert wurde. Die aktuelle Lokalität wird eben nur approximiert. Die Arbeitsmenge enthält möglicherweise auch Seiten die nur einmal benutzt wurden. Der Übergang zu einer neuen Lokalität erfolgt nur allmählich.
Gefahr bei Seitenaustauschverfahren
Gefahr des Seitenflatterns (Trashing). Bei Überlastung mit zu vielen Prozessen die entweder zu viele Pagefaults produzieren und/oder zuwenig Seitenrahmen zur Verfügung haben, ist der Rechner weitgehend mit dem Ein-/und Auslagern von Seiten beschäftigt und kann an den eigentlichen Aufgaben der Prozesse kaum noch weiterarbeiten. Effektive CPU Auslastung sinkt durch viele Seitenfehler. Weitere Gefahr besteht dann durch zu einfach konstruierte Scheduler, die bei sinkender CPU-Auslastung mit einer höheren Prozessintensität reagieren. Page Damons können dem Abhilfe schaffen, weil sie Prozesse auslagern, wenn nicht mehr ausreichend Seitenrahmen im Speicher zur Verfügung stehen.
Was kann man gegen Trashing (Seitenflattern) tun?
Man sollte Page Dämons benutzten, denn dadurch wird die Anzahl der gleichzeitig aktiven Prozesse verringert und jedem Prozess stehen mehr Seitenrahmen zur Verfügung.
Wie wird die Seitengröße festgelegt?
Die Seitengröße ist normalerweise klein. Dies hat verschiedene Gründe sie klein zu halten, aber auch einen wichtigen Grund, die Größe nicht zu klein zu definieren. Im Mittel ist die letzte Seite eines Codestückes nur halb gefüllt, da logischerweise nicht jedes Code, Stack oder Datensegment genau in eine Seite passen kann oder sich so auf mehrere verteilt, daß kein freier Speicher mehr verbleibt. Des Weiteren muss beachtet werden, dass es auch viele kleine Segment gibt. Angenommen man legt eine Seitengröße von 32 KB fest, so werden bei 4 KB großen Segmenten stets 28 KB verschwendet. Andersherum benötigt man mit kleinen Seiten eine größere Seitentabelle, deren Anzahl proportional zur Seitengröße ist. Des Weiteren muss man einkalkulieren, daß das Einladen einer Seite von Platte eine langwierige Operation ist. Es ist trivial das das Einlagern von vier 8K-Seiten schneller ist, als das Einlagern von 64 512 Byte großen Seiten. Es muss also ein Mittelweg gefunden werden, welcher einen optimalen Nutzen aus den oben genannten Kriterien zieht.
Verschwendung = Prozessgröße * Seitentabelleneintragsgöße / Seitengröße + Seitengröße / 2
Die Nullstellenberechnung der ersten Ableitung in Abhängigkeit der Seitengröße ergibt:
Optimale Seitengröße = Wurzel aus 2 * Prozessgröße * Seitentabelleneintragsgöße
Kapitel 8 - Deadlocks
Die notwendigen Bedingungen für Deadlocks
- Mutual Exclusion (z.B. via Druckerspooler über Ersatz-BM Buffer aufgelöst)
- Belegungs- und Wartebedingung (Prozess kann weitere BM anfordern)
- Unterbrechbarkeitsbedingung (BM können nicht entzogen werden)
- zyklische Wartebedingung (Zyklus im Betriebsmittelgraph)
Was sind die hinreichende Bedingungen für Deadlocks?
Es darf keine externe Betriebsmittelinstanz bestehen.
Livelocks
Es wurde ein Betriebsmittel vergeben, es besteht aber keine Verhinderung. Das BM könnte irgendwann wieder freigegeben werden, aber der Zeitpunkt unbekannt.
Z.B. Priotitätsscheduling (langwierige Prozesse verhungern da benachteiligt)
Wie kann man Deadlocks auflösen oder umgehen?
- Vogel-Strauß Algorithmus (einfach Ignorieren)
- Versuchen zu Erkennen und zu beheben (Topologische Sortierung des BM-Graphs oder Vektoren-Matrix Variante)
- dynamisches Verhindern (vor Zuteilung auf Deadlock prüfen)
- konzeptionelles Vermeiden (eine der notwendigen Bedingungen eliminieren)
Welche Prozesse sind an einem Deadlock beteiligt?
Prozesse die mehrere Betriebsmittel mit jeweils exklusiven Zugriff benötigen.
Wie kann man Deadlocks (im Voraus) erkennen?
Die zur Ausführung eines Prozesses notwendigen Betriebsmittel müssten vor Ausführung bekannt sein. Das ist aber in einem offenen System nicht möglich. Das Prinzip ist das gleiche wie das Preclaiming im DBMS. Erst wenn alle angeforderten Betriebsmittel verfügbar sind, führt der Prozess den nächsten Schritt aus. Algorithmisch wäre dies durch zyklische Prüfung (für jeden Prozeß) auf Vorhandensein der erforderlichen Betriebsmittel erreichbar.
Wie werden Deadlocks beseitigt?
Durch Abbruch der beteiligten Prozesse und Freigabe der belegten Betriebsmittel. Siehe optimistische Sperrverfahren bei DBMS.
Wie können Deadlocks vermieden werden?
Möglichkeit 1
Es müsste bei jeder Betriebsmittelanforderung geprüft werden, ob diese zu einem Deadlock führen würde. Da dies sehr aufwendig ist, wird so nicht verfahren.
Möglichkeit 2
Bei Anforderung zusätzlicher Betriebsmittel werden alle bisher reservierten Betriebsmittel freigegeben und dann zusammen mit den zusätzlichen Betriebsmitteln erneut angefordert (Form von Preclaiming).
Möglichkeit 3
Betriebsmitteltypen werden linear nach Priorität angefordert . Falls schon Betriebsmittel reserviert sind, können keine Betriebsmittel, die wichtiger sind als die schon reservierten, angefordert werden. Damit wird zyklisches Warten unmöglich (ähnelt dem 2-Phasen-Sperrprotokoll). Problem ist aber die Vergabe geeigneter Nummerierungen, da reale und abstrakte Betriebsmittel (z.B. Spoolbereiche auf Festplatten) sich nur schwer Ordnen lassen.
Möglichkeit 4
Der Banker Algorithmus als Verfahren zur Erkennung sicherer Systemzustände bei der Verteilung von Ressourcen.
Der Bankieralgorithmus
Ein Banker hat einen bestimmte Menge einer Ressource. Jeder Kunde hat ein Limit, bis zu dem er Ressourcen vom Banker erhalten kann. Der Banker hat aber so viele Ressourcen, daß er das größte vorhandene Limit gerade noch bedienen kann. Der Kunde bekommt die Ressource, falls der Banker danach noch genügend Ressourcen hat, um mindestens einem der Kunden sein komplettes Limit zuteilen zu können.
Beispiel Bankieralgorithmus
Der Banker habe 10 Einheiten eines Betriebsmittels verfügbar.
- Das Limit von Kunde A betrage 8 Einheiten.
- Das Limit von Kunde B ist 7 Einheiten.
- A hat zur Zeit 5 Einheiten belegt
- und B hat 2 Einheiten reserviert
Falls B nun eine weitere Einheit anfordert, so muss dies verweigert werden, da dann der Banker nur noch 2 Einheiten übrig hätte, diese aber nicht zur Befriedigung einer kompletten Reservierung von A oder B ausreichen würde und zu einem Deadlock führen würde. Solch ein Zustand heißt unsicherer Zustand. Der Problem ist nun, daß jeder Prozeß muß im Voraus wissen muss, wieviele Einheiten eines Betriebsmittels er maximal während seiner Abarbeitung benötigen wird.
Warum funktioniert die Deadlock-Vermeidung bei linearer Ordnung der Betriebsmittel?
Prozesse können zwar alle Betriebsmittel anfordern, aber alle Anforderungen müssen gemäß der Nummerierungsreihenfolge geschehen. Somit ist es von vornherein ausgeschlossen, daß ein Prozeß der ein Betriebsmittel höherer Ordnung besitzt, ein Betriebsmittel niedrigerer Ordnung, das von einem anderen Prozeß belegt ist, anfordern kann. Also werden Schlingen im Wartegraph und damit Deadlocks vermieden, da nun eine notwendige Voraussetzung für Deadlocks eliminiert wurde. Umgesetzt kann das Ganze durch eine Nummerierung der Betriebsmittel werden. Das Prinzip ähnelt dem Zeitstempelverfahren bei DBMS.
Kapitel 9 - Dateisysteme
Hier geht es im Besonderem um Verwaltung, Zugriffsoptimierung und die Umsetzung einer für den Menschen vereinfacht nutzbaren Abstraktion. Der Zugriff auf Daten erfolgt nicht wie beim Hauptspeicher Byte-orientiert, sondern aus Effizienzgründen blockweise, da Platten um ein vielfaches langsamer als Arbeitspeicher sind. Des Weiteren sind bis auf einige Ausnahmen, wie CD ISO9660, die meisten Dateisysteme Betriebssystemspezifisch.
Was ist eine Datei?
Eine Datei ist ein logisches Betriebsmittel, welches eine endliche Menge zusammengehöriger Daten beinhaltet. Verzeichnisse sind spezielle Dateien, welche zur Strukturierung von Dateisystemen eingeführt wurden.
Welche Möglichkeiten der Freispeicherverwaltung von File Systemem gibt es?
- Kontinuierliche Allokation - schlecht wenn Datum angehangen werden soll
- Verkettete Listen - schlecht, da Wahlfreier Zugriff extrem langsam
- Listen mit Zuordnungstabellen - Zuordnungstabellen erlauben schnellen wahlfreien Zugriff (FAT)
- Indizierte Speicherung
- Indirekt indizierte Speicherung
Ein leeres Dateisystem wird als lineares Medium betrachtet und nach und nach linear aufgefüllt. Vorteil dieser Variante ist schneller Zugriff. Nachteil ist die extreme externe Fragmentierung bei Änderungen von Dateigrößen.
Das Prinzip der verketteten Listen
Listen sind langsamer als kontinuierliche Allokation, bieten nur wahlfreien Zugriff und besitzen nur geringe Fehlertoleranz. Dafür werden aber nur sehr wenig Verwaltungsdaten benötigt. (Hier nur Pointer auf den nächsten belegten Block) Eine Verbesserung der Effizienz wird durch das Nutzen doppelt verketteter Listen erzielt, wobei sich aber auch der Zahl der Verwaltungsdaten verdoppelt.
Das Prinzip der Listen mit Zuordnungstabellen
Hier werden die Nutzdaten von den Zeigern in eine extra Tabelle ausgelagert. Die Dateizuordnungstabelle am Bsp. FAT enthält für jeden Block einen Eintrag mit einem Verweis auf den Folgeblock oder einen bestimmten Eintrag für EOF. Die Effizient wird hier bei großen Tabellen eingeschränkt.
Indizierte Speicherung
Für jede Datei wird hier die Startadresse und die Indexlänge gemerkt. So ist zwar schneller wahlfreier Zugriff möglich, aber es herrscht das gleiche Problem der externen Fragmentierung wie bei kontinuierlicher Allokation. Die Geschwindigkeitssteigerung gegenüber Zuordnungstabellen kommt daher, dass Zusammenhängende Blöcke in Zuordnungstabellen nicht hintereinander liegen, sondern verstreut in der Tabelle. Die indizierte Speicherung führt sogenannte Indexblöcke ein, in welche hintereinander die zur Datei gehörigen Blocknummern eingetragen werden. So muss bei einem Zugriff im Worst Case nicht die ganze Zuordnungstabelle nach den Blocknummern durchsucht werden.
Wie groß sollte nun aber so ein Indexblock gewählt werden? Variable längen sind schlecht realisierbar. Wählt man sie zu groß, geht Speicher durch interne Fragmentierung verloren. Wählt man sie zu klein, beschränkt man die Dateigröße... Deshalb wurde die indirekt indizierte Speicherung eingeführt.
Indirekt indizierte Speicherung
Ein Eintrag im Verwaltungsblock (Indexblock) zeigt wieder auf einen oder mehrere Blöcke, die nun die Verweise auf die wirklichen Datenblöcke enthalten, oder wiederrum auf weitere Indexblöcke. (Dreifach Indirekt) So ist auch auf große Dateien der Zugriff gewährleistet.
Was ist das Besondere an Unix FS Ext 2?
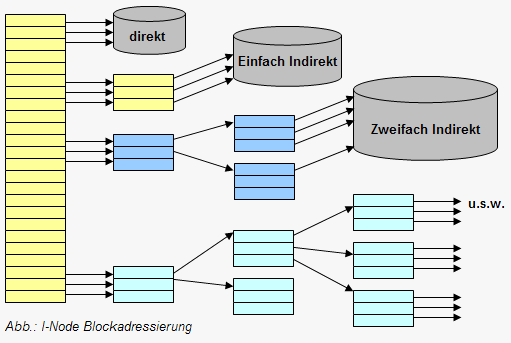
Es werden Inodes für den Zugriff auf Datenblöcke verwendet. Die Dateinamen werden in einer extra Tabelle verwaltet, welche die Attribute (Eigentümer, Zeiten, Größe) und 12 direkte Zeiger auf Blockadressen (einfach, doppelt, dreifach indirekt) enthält.
Festplatten-Scheduling-Algorithmen
- First Come First Serve
- Shortest Seek Time First (Sektor mit kürzesten Suchzeit suchen)
- Scan (Diskarm bewegt sich von einem Ende zum Anderen und bearbeitet Requests)
- C-Scan (Diskarm wird bei Erreichen des Endes wieder auf Anfang zurückgesetzt - kreisförmig)
- Look (Wie C-Scan, nur wird nur so weit wie notwendig zurückgesetzt)
- Look (Wie C-Look, nur kreisförmig)
Welche Bewertungskriterien für Festplattenalgorithmen gibt es?
- Caching
- Demand Paging wichtiger als E/A der Anwendungen
- Robustheit nach Systemabstürzen
- Berücksichtigung der hohen Rotationsgeschwindigkeiten moderner Platten
- Verzeichnisse und Indexblöcke sollten in mittleren statt äußeren oder inneren Zylindern sein, da dort die mittlere Zugriffszeit am kleinsten ist (im Durchschnitt befindet sich der Lesekopf in der Mitte)
Die FAT - File Allocation Table
Die FAT Dateizuordnungstabelle liegt auf den ersten Spuren einer Platte. Sie wird aus Sicherheitsgründen oft gesichert. Alle Blöcke einer Platte sind über die FAT miteinander verkettet (abgesetzte verkettete Allokation). Die Größe einer Zuordnungseinheit ist für eine Partition statisch, kann sich aber zwischen den Partitionen unterscheiden (üblich sind 512, 1024 oder 4096 Bytes). FAT bietet weder Schutzmechanismen, noch unterstützt es lange Dateinamen (erst ab VFAT).
Welche Verzeichniseinträge hat FAT?
- Dateiname (8+3 Zeichen)
- Attribut-Byte
- Zeit und Datum der letzten Bearbeitung
- Erste Zuordnungseinheit der Datei
- Dateilänge
Das Dateisystem assoziiert eine Baumstruktur. Für jede Datei enthält die Dateizuordnungstabelle eine lineare, gezeigerte Liste, mit der die Blöcke der Datei bzw. des Unterverzeichnisses bestimmt werden können. Der Index der Tabelleneinträge stellt die Blocknummer der Festplatte dar.
NTFS
NTFS heißt New Technology File System. NTFS ist mit einem Zugriffsschutz ausgestattet und hat auch keine Größenbegrenzung mehr. Ein Logfile wird verwendet, um nach einem Systemausfall Daten rekonstruieren zu können. NTFS besitzt nur Dateien. Analog zu den I-Nodes beim Unix gibt es beim NTFS eine Master File Table, in welcher jede Datei einen Eintrag besitzt. Zusammenhängende Bereiche (extents) werden als B-Baum organisiert.
Was ist die MFT von NTFS?
Bei kleinen Dateien bzw. Verzeichnissen werden alle Attribute (incl. der Daten) innerhalb des MFT-Eintrages abgelegt (bis zu 1 bis 4 KB). Ein Eintrag in der MFT benötigt einen oder mehrere Sätze der MFT (Satzlänge ist konfigurierbar). Bei großen Dateien enthält der MFT-Eintrag den Wurzelknoten eines B-Baums, dessen "Blätter" die Verweise auf die zusammenhängenden Dateibereiche (Extent oder Lauf) enthalten.
Ähnlich wie die Inode-Tabelle beim UNIX-System stellt die MFT ein flaches Dateisystem dar. Über die Verzeichnisse wird darauf die bekannte Baumstruktur definiert.
Wie werden unter NTFS Dateien eindeutig identifiziert?
Jede Datei ist eindeutig über eine ID identifizierbar. Diese ID ist die Satznummer ihres Eintrages in der MasterFileTable (48 Bit). Zusätzlich wird eine Folgenummer (16 Bit) angehängt, die bei jedem Bezug auf den MFT-Eintrag (z.B. beim Öffnen der Datei) um 1 erhöht wird (für Konsistenzüberprüfungen)
Wie werden unter NTFS Verzeichnisse umgesetzt?
Ein Verzeichniseintrag besteht aus dem Dateinamen, der ID-Nummer der Datei bzw. des Unterverzeichnisses, einer Kopie der Update-Zeit und der Dateilänge aus dem MFT-Eintrag. Verzeichnisse werden nicht wie bei FAT in einer linearen Liste verwaltet, sondern als B-Baum.
Spezialdateien von NTFS
- MasterFileTable (MFT)
- MFT2: enthält die ersten 16 Einträge der MFT als Backup
- Eine Logdatei (Daten über Transaktionen zum Wiederherstellen der Daten- bzw. der Dateisystemkonsistenz)
- Datenträgerdatei enthält den Namen des Datenträgers, Versionsnummer des Dateisystems und eventuellen Verdacht auf Inkonsistenz
- Wurzelverzeichnis
- Cluster-Bitmap-Datei für belegte und freie Cluster des Datenträgers
- Bootdatei mit dem Startcode für NT
- BadClusterDatei, welche Verweise auf defekte Cluster enthält
I-Nodes des Unix Dateisystems
Die ersten Adressen von Plattenblöcken sind in dem I-Node gespeichert. Diese Adressen reichen aber nur für kleine Dateien aus. Für größere Dateien, welche nicht durch ein I-Node adressierbar sind, gibt es Adressen in dem I-Node, die die Adresse eines Plattenblockes enthalten, welcher weitere Plattenadressen enthält. Dieser Block wird "einfach indirekter Block" genannt. "Einfach indirekte" Blöcke verweisen auf Blöcke, die ihrerseits eine Reihe von direkten Blocknummern enthalten. Beim Zugriff auf Daten über einen indirekten Block muß der Kern zuerst diesen indirekten Block lesen, den passenden direkten Blockeintrag ermitteln und dann diesen Block lesen. Es gibt auch Adressen, die auf Blöcke zeigen, die die Adressen von einfach indirekten Blöcken enthalten. Solche "doppelt indirekten" Blöcke enthalten eine Liste indirekter Blocknummern. Blöcke mit dem Kennzeichen "dreifach indirekt" enthalten eine Liste von doppelt indirekten Blocknummern u.s.w.
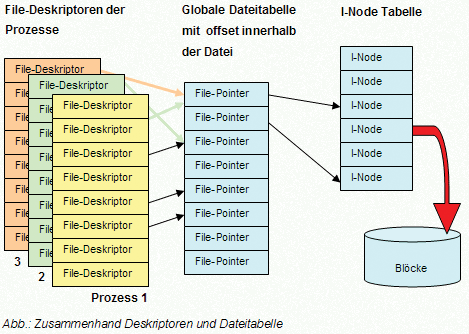
Dateideskriptoren
Jedem Prozess ist eine eigene Benutzer-Filedecriptor-Tabelle zugeordnet. Ruft ein Prozess open oder create holt der Systemkern einen freien Inode aus der Inode-Tabelle und übergibt diesen an die globale Dateitabelle und erzeugt einen Eintrag in der Benutzer-Filedecriptor-Tabelle.
Was enthält die globale Dateitabelle des Systems?
Den Offset in Byte zum Dateianfang für den nächsten read- bzw. write-Befehl des Benutzers und die Zugriffsberechtigungen für den Prozeß, der die Datei eröffnet hat. Die Benutzer-Filedecriptor-Tabellen enthalten dagegen nur die geöffneten Dateien eines Prozesses.
Was beinhaltet ein I-Node?
- Dateityp
- Eigentümer
- Gruppe des Eigentümers
- Zugriffsschutzbits
- Datumseinträge
- Anzahl der Links für diesen I-Node
- Zeiger auf den Dateiinhalt
Geräte als I/O Dateien
Es gibt zwei Klassen solcher Dateien. Blockorientierte Spezialdateien und Zeichenorientierte Spezialdateien.
Blockorientierte Spezialdateien
Blockorientierte Spezialdateien werden benutzt, um Geräte zu modellieren, die aus frei adressierbaren Blöcken bestehen. ( random access devices wie Festplatten). Wird eine blockorientierte Spezialdatei geöffnet, so kann ein Block gelesen werden, ohne daß man sich um die Struktur des Dateisystems, das dies ermöglicht, kümmern zu müssen.
Zeichenorientierte Spezialdateien
Diese werden benutzt, um Geräte zu modellieren, die aus Zeichenströmen bestehen. Beispiele hierfür sind Terminals, Drucker, Netzschnittstellen. Ein Programm schreibt auf das entsprechende I/O-Gerät, indem es in die korrespondierende zeichenorientierte Spezialdatei schreibt. Analoges gilt für das Lesen.
Wie ist das Unix Dateisystems aufgebaut?

Der Bootblock ist meistens im ersten Sektor einer Partition. Er enthält den Bootstrap-Code, der beim Hochfahren eines UNIX-Rechners in den Speicher gelesen wird. Er lädt bzw. initialisiert das Betriebssystem.
Der Superblock beschreibt den Aufbau des Dateisystems. Eine Kopie des Superblocks befindet sich permanent im Speicher. Der Kern schreibt periodisch den Superblock auf die Platte zurück, so daß er immer mit den aktuellen Daten im Dateisystem übereinstimmt. Der Superblock enthält folgende Felder:
- Größe des Dateisystems
- Anzahl der freien Blöcke
- Liste der freien Blöcke
- Index auf den nächsten freien Block
- Größe der I-Nodeliste
- Anzahl der freien Inodes im Dateisystem
- Liste der freien Inodes
- Index auf den nächsten freien Inode in dieser Liste
- Sperrkennzeichen für die Listen freier Blöcke und Inodes
- Flag für durchgeführte Änderungen im Superblock
Wie kann ein Prozeß auf Daten auf der Festplatte zugreifen?
- Das virtuelle Gerät hinter dem die Festplatte verborgen wird, heißt Datei.
- Der Prozeß öffnet die Datei und erhält eine Datei-ID die auf eine Datei-Deskriptor-Tabelle verweist.
- Es folgt die Adressierung der Sektoren.
- Über die Sektoradresstabelle (FAT oder I-Node Tabelle) werden die Adressen der Blöcke ermittelt
- Es folgt die Übertragung der Blöcke zum Hauptspeicher
- Zugriff erfolgt nach speziellem Prinzip, wie z.B. SSN
- zur Minimierung der Suchzeit muss Wahl einer effizienten Positionierungsstrategie
- Durch einen Interrupt oder ein spezielles Register teilt der Controller dem BS das Ende der Übertragung mit.
Wie wird eine Datei unter Unix gesucht?
Linux identifiziert Dateien indirekt über den absoluten Pfadnamen, indem es
durch diesen den dazugehörigen I-Node sucht. Jede Datei wird durch einen oder
mehrere I-Nodes beschrieben. Die I-Nodes enthalten die Blockadressen der Datei. Ein
Katalog (Verzeichnis) enthält alle im Verzeichnis enthaltenen Datei- bzw.
Verzeichnisnamen und die dazugehörigen I-Nodes.
Unix Beispielzugriff
- Es soll die Datei /var/log/messages betrachtet werden
- Der I-Node des Wurzelverzeichnisses "/" steht an einer definierten Stelle auf der Platte
- Es wird das Verzeichnis "var" im Wurzelkatalog (auch eine Datei) gesucht
- In diesem Katalog steht der dazugehörige I-Node der auf das Verzeichnis bzw. den Katalog "var" verweist
- nun wird in der Katalogdatei "var" nach "log" gesucht und der dazugehörige I-Node gelesen
- Nun kann über den I-Node nach dem Eintrag "messages" in "log" gesucht werden
- Der I-Node der Datei "messages" wird nun in die globale Dateideskriptortabelle und die lokale Deskriptortabelle des Prozesses geladen
- Dieser Dateideskriptor ist das Handle, mit dem der Prozess auf die Datei zugreifen kann
- Nach eine Close() wird der I-Node aus der Dateideskriptorliste wieder entfernt.
Quellen
Andrew S. Tanenbaum
Computerarchitektur
Andrew S. Tanenbaum
Moderne Betriebssysteme
Petterson
Computer Architectur & Design
Christian Märtin
Rechnerarchitekturen
Kalfa
Skript und Vorlesung