Rechnerarchitektur
Grundprinzipien der Rechnerarchitektur. D.h. Themen wie RISC, Branch Prediction oder Tomasulo.
Kapitel 1 - Prinzipien und Architekturen
In welche sieben Ebenen kann man ein Rechnersystem einteilen?
- Anwendungsebene (Anwendersoftware)
- Assemblerebene (Beschreibung von Algorithmen, Link & Bind)
- Betriebssystem (Speichermanagment, Prozesskommunikation)
- Instruction Set Architecture (ISA,Adressierungsarten)
- Microarchitektur (Risc,Cisc,Branch Prediction..)
- Logische Ebene (Register,Schieber, Latches..)
- Transistorebene (Transistoren, MOS )
Wie lassen sich Architekturen klassifizieren?
Nach ihrem Rechenprinzip
- Von Neumann (Steuerfluss)
- Datenfluß (Zündregel)
- Reduktion (Funktionsaufruf)
- Objektorientiert (Methodenaufruf)
Nach dem Architektur-Grundkonzept
- Vektorrechner (Pipeline)
- Array-Computer (Data-Array)
- Assoziativ-Rechner (Assoziativ-Speicher)
Wie kann die Leistung erhöht werden?
| Über die Architektur | Pipelines, Superskalarität, Spekulative Ausführung, Caches, Busbreite |
| Über Optimierung von Software | Compileroptimierung |
| Über die Siliziumbasis | Transistordichte und Taktraten |
Was sind die vier Hauptbestandteile eines typischen Rechners?
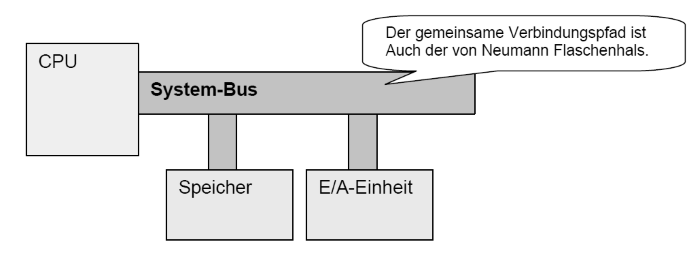
Was unterscheidet eine Schnittstelle von einem Bus?
Ein Bus verbindet mehr als zwei Teilnehmer.

John von Neumann mit ENIAC
Welche Bestandteile definieren einen von Neumann-Rechner?
Der von Neumann-Rechner arbeitet sequentiell, Befehl für Befehl wird abgeholt, interpretiert, ausgeführt und das Resultat abgespeichert.
- Steuerwerk (Taktgeber und Befehlszähler)
- Speicher
- Rechenwerk (CPU)
- I/O-Einheit
Datenbreite, Adressierungsbreite, Registeranzahl und Befehlssatz können als Parameter verstanden werden.
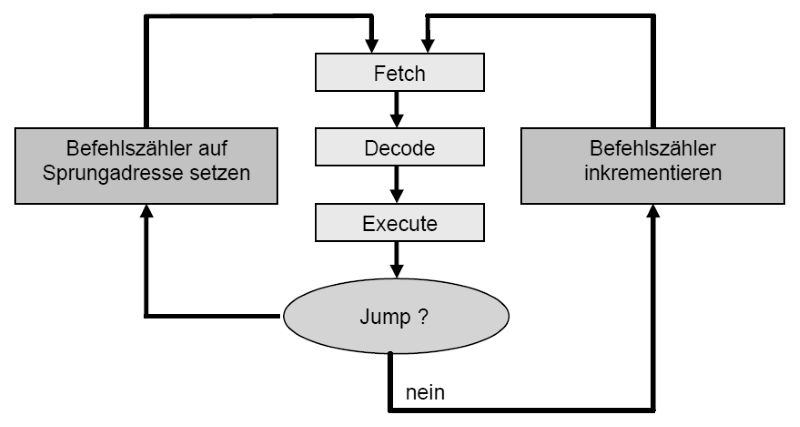
Wie arbeitet die zentrale Befehlsschleife eines Von-Neumann-Rechners?
Was heißt Havard-Architektur?
Daten- und Befehlsspeicher sind getrennt. So ist es möglich Daten und Befehle Zeitgleich aus dem Speicher zu holen. Da dies aber einen extrem hohen Aufwand bedeutet, wird dies nur bei Echtzeitanwendungen implementiert.
Was ist ein Taktzyklus?
Die Interpretation und Ausführung eines Befehles erfolgt in vier Phasen.
- Holen
- Dekodieren (inklusive Operandenadressen berechnen)
- Daten holen (bzw. Operanden)
- Ausführen
Jede der vier Phasen wird in eine Anzahl von Schnittstellen bzw. Zyklen eingeteilt. Ein Taktzyklus ist die kleinstmöglich verarbeitbare Einheit. Somit benötigt ein Befehl zur Ausführung im Allgemeinen mehr als einen Taktzyklus.
Was ist Mikroprogrammierung?
Durch Einsatz von Matrix-Speichertechnologie ist es möglich Steuersignalkombinationen in je einer Zeile dieser Speichermatrix abzulegen. Somit können Zeile für Zeile Maschinenzustande auf dem Prozessor hinterlegt werden. Das sogenannte Mikroprogramm. Die interne Logik ist eher zufällig optimiert. Daher der Begriff "Random Logic".
Was sind Complex Instruction Set Computer (CISC)?
Durch Einführung von mnemonischen Kodierungen von Mikrobefehlen, welche von Mikrobefehls-Assemblern verarbeitet werden, sind weitaus komplexere Befehle möglich. CISC bietet einen sehr großen Befehlssatz mit sich start unterscheidenden Befehlen in Ausführungszeit und Parameterliste.
Gegenüberstellung der Architektur von CISC und RISC
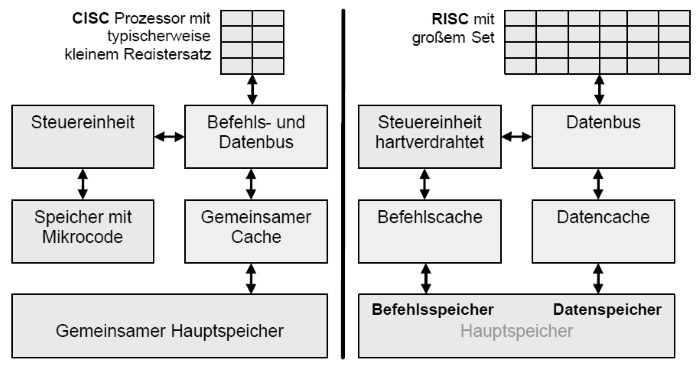
Worin unterscheiden sich RISC und CISC besonders?
| Eigenschaften | CISC | RISC |
| Register | Wenige Register( ca. 20) | Viele Register (bis zu 200) und Registerfenster |
| Befehlssatz | ca. 300 Befehle und mehr als 50 Befehlstypen | Nur rund 100 meist registerorientierte Befehle (außer LOAD / STORE) |
| Adressierungsarten | ca. 12 verschiedene | Nur 3 bis 5 Arten und nur LOAD/STORE zum Speicher |
| Caches | Gemeinsame Caches, aber später auch Getrennte | Getrennte Daten- und Befehlscaches nach Harvard |
| CPI | 1 bis 20 - Durchschnittlich 4 | 1 bei Basisoperationen - im Schnitt 1,5 |
| Befehlssteuerung | Mikrocode im Speicher, aber auch hartverdrahtet | Meistens hartverdrahtete Mikroprogramme ohne Mikroprogrammspeicher |
| Beispielprozessoren | Intel x86, AMD, Cyrix | Sun UltraSparc, PowerPC |
Welche Befehlssatz-Architekturen kennen Sie?
Stack-Architektur?
Diese Form benötigt keine Adressen für Operanden und ist somit eine Nulladressmaschine. Quell und Ergebnisoperanden liegen auf einem Operanden-Stack. Vorteil dieser Architektur ist daher die Speicherplatzeinsparung durch die nicht notwendigen Adressen.
Akkumulator-Architektur?
Um Verknüpfungsoperationen durchzuführen, liegt ein Operand in einem Register und ein Operand typischerweise im Hauptspeicher (Einadressmaschine) . Vorteil ist die einfache Implementierung, da nur ein internes Register benötigt wird. Nachteil ist aber die hohe Speicherlast.
Universalregister-Architektur?
Ein Satz von gleichberechtigten Registern kann zum Ablegen von Daten genutzt werden. Deshalb sind im Op-Code mehrere Operanden anzugeben (Zwei-, Dreiadressmaschine etc.) Vorteil ist die freie Benutzbarkeit durch Compiler. Ausdrucksberechnungen können somit in beliebiger Reihenfolge erfolgen, was Pipelining möglich macht. Dazu kommt, daß die Speichertransferlast sinkt, die Geschwindigkeit steigt und Superskalartechniken sind effizient einsetzbar. Der Nachteil dieser Architektur sind die teilweise großen Registersets, welche bei jedem Kontextwechsel auszutauschen sind. Außerdem müssen die Operanden Adressiert werden, was zu langen Befehlen führt.
Welche Register-Architekturen gibt es?
Register-Register ohne Speicheradressen (Sparc,Mips)
Verknüpfungsoperationen verwenden nur Register. Nur in Lade- und
Speicherbefehlen werden Adressen verwendet. (Load / Store -
Architektur). Vorteil ist, dass die Verknüpfungen immer mit Registern
geschehen und somit eine Befehlsdekodierung mit fester Länge möglich ist.
Vorteile
- Einheitliche Taktzyklen pro Befehl
- Pipeline-Prinzip wird dadurch unterstützt
Nachteile
- Code wird größer, da Speichertransfers nur durch zusätzliche Befehle
Register-Speicher mit der Möglichkeit von Speicheradressen (Motorola 68000)
Vorteile
- Daten können auch im Speicher referenziert werden, ohne diese vorher
- Explizit laden zu müssen.
Nachteile
Durch die variierenden Adressierungen variieren Befehlslänge und Taktzyklen pro Befehl, was äußerst negativ für Verfahren wie Pipelining ist.
Speicher-Speicher mit nur Speicheradressen (DEC-VAX)
Vorteile
Der Programmierer braucht sich nicht um Register kümmern. Deshalb wird die Programmierung transparenter.
Nachteile
Es entsteht ein hoher Speicherverkehr, was sich Nachteilig auf die Performance auswirkt. Falls doch Register erlaubt werden (Orthogonaler Befehlssatz / CISC), variieren auch hier Befehlslänge und Taktanzahl pro Befehl.
Orthogonale Befehlssätze sind solche, welche eine beliebige Kombination von Befehlscode, Adressierungsart und Datentyp zulassen.
Was ist Byte-Ordering und Word-Alignment?
Alle konventionellen Rechner sind Byte-Adressiert. D.h. das Worte (egal ob 8, 16 oder mehr Bit) bestehen aus einer Folge (aufsteigender) Bytes. Dabei gilt das erste Byte als die Adresse des Wortes. Nimmt die Wertigkeit mit aufsteigender Adresse zu, ist es das Litte-Endian-Format, umgekehrt das Big-Endian-Format.
Falls Worte so in den Speicher passen, das keine Verschiebungen auftreten, heißt der Speicher aligned. Prüfen kann man dies durch die Formel
Adresse mod Wortlänge = 0?
Kapitel 2 - Interrupts und DMA
Klassifizieren Sie die verschiedenen Unterbrechungen!
Wenn in der Literatur von Interrupts gesprochen wird, so werden oft externe, asynchrone Interrupts gemeint, welche meistens in Zusammenhang mit E/A-Geräten auftreten.
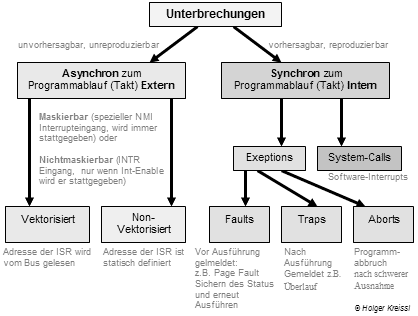
Wie arbeiten Traps (Fangstellen?)
Traps sind eine Art automatische Prozeduraufrufe, welche durch eine vom Programm verursachte Bedingung eingeleitet werden. Solch eine Bedingung kann z.B. Gleitkommaüberlauf, Schutzverletzung oder Stapelüberlauf. Findet ein Überlauf statt, so stoppt die Ablaufsteuerung die Ausführung und holt von einer bestimmten Stelle im Speicher die Adresse des Trap-Handlers (Prozedur), mit der dann der Programmcounter überschrieben wird.
Wesentliches Merkmal eines Traps ist, daß es durch Ausnahmebedingungen ausgelöst wird, welche durch Hardware oder Mikroprogramme erkannt werden.
Wie arbeiten Interrupts
Interrupts sind Unterbrechungen der Ablaufsteuerung. Wie es für Traps Trap-Handler gibt, gibt es für Interrupts Interrupt-Handler. Nach Abarbeitung des Interrupt-Handlers wird die Kontrolle wieder an das Programm zurückgegeben. Der interne Zustand des Prozessors (IP, Register, ...) muss nun exakt wiederhergestellt werden.
Der Unterschied zwischen Traps und Interrupts ist nun, daß Traps synchron mit dem ausgeführten Programm laufen. Deshalb werden sie auch erst nach der Befehlsausführung erkannt und ausgeführt. Asynchrone Interrupts sind dagegen unabhängig vom gerade ausgeführten Programm.
Interrupt’s stammen von echten physikalischen INT-Quellen wie z.B. IRQ3 von COM1 kommt. Diese springen über ein Interrupt-Gate. Interrupt’s die per Software mit INT-Befehl ausgelöst werden, springen über Trap-Gates! Wenn ein Interrupt ein Interrupt-Gate durchläuft, wird das IF=0 automatisch gesetzt, d.h. es gehen überhaupt keine Interrupts mehr durch. Asynchrone Interrupts können also nicht unterbrochen werden. Trap-Gates dürfen unterbrochen werden, da sie nicht zeitkritisch sind. Interrupt- und Trap-Gates führen nicht zu Taskwechsel über ein TSS. Das retten der Register ist dem INT-Handler überlassen.
Was sind Software Interrupts?
Software-Interrupts werden von Programmen mit Hilfe von speziellen Maschinenbefehlen aufgerufen. Dabei müssen diese nur eine Nummer für das benötigte Interrupt kennen. Über diese Nummer wird in der Interrupt-Vektor-Tabelle die Adresse des Interrupt-Unterprogrammes (ISR) referenziert und ausgeführt.
Was versteht man unter internen und externen Interrupts?
Externe Interrupts sind asynchron, wie nichtvektorisierte und vektorisierte Interrupts. Interne sind synchron, wie Software Interrupts oder Exection-Traps (Reaktionen auf interne Fehler wie FPU-Errors oder Page-Faults).
Was ist Polling?
Polling ist das zyklische Abfragen von einen oder mehreren E/A-Devices zur Feststellung der Kommunikationsbereitschaft bzw. zum Einholen von Kommunikationswünschen.
| Vorteile des Pollings | Nachteile des Pollings |
| Einfach zu Implementieren | Hoher Programm-Overhead |
| Kommunikationsanforderungen erfolgen synchron zum Programmablauf | Die meisten Anfragen an die Geräte sind unnötig |
| Je mehr Geräte am Bus hängen, um so mehr steigt Reaktionszeit. | Priorisierung bei zeitgleichen Anfragen erfordert zusätzlichen Zeitaufwand |
Aufgrund der vielen Nachteile sollte besser eine asynchrone Kommunikation mit den Geräten durch die Hardware unterstützt werden (Interrupts).
Das Interrupt-Prinzip
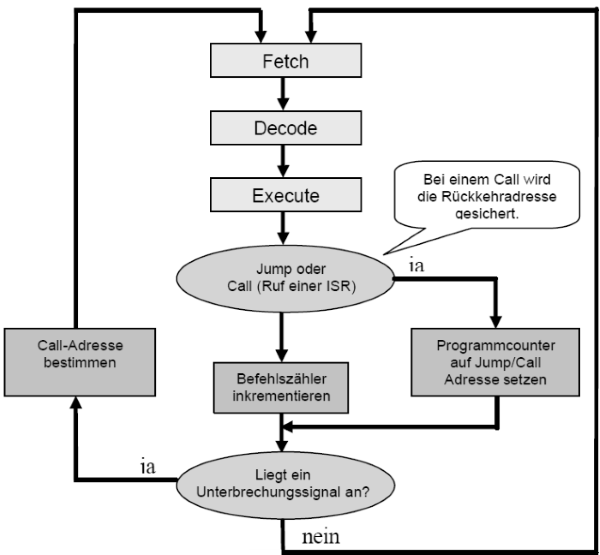
Es kann auch über eine Art "hardware-gestütztes Polling" über spezielle Interrupt-Signalleitungen eine Kommunikationsanforderung festgestellt werden. Dazu muss aber die Befehlsverarbeitungschleife um eine Unterbrechungsanfrage erweitert werden.
Erklären Sie den Unterschied zwischen vektorisierten und nichtvektorisierten Interrupts!
Man unterscheidet vektorisierten und nichtvektorisierten Interrupt. Bei nichtvektorisierten Interrupts wird dem Interruptsignal eine feste Adresse zugeordnet. Bei vektorisierten Interrupts wird dynamisch eine wahlfreie Adresse zugeordnet, welche durch die CPU über ein definiertes Protokoll vom Datenbus gelesen wird.
Was passiert beim Auftreten eines Interrupts?
1. Sperren weiterer Unterbrechungen mit gleicher oder geringerer Priotität
- Unterbrechungen mit höherer Wichtigkeit dürfen normalerweise solche mit geringerer Wichtigkeit wieder unterbrechen
2. Rettung wichtiger Register-Informationen(Prozessorstatus)
- alle Prozessor-Register retten, die durch die Interruptbehandlung überschrieben würden
- heute gibt es dafür spezielle Maschinenbefehle
3. Bestimmen der Interruptquelle (durch Hardware realisiert)
4. Laden des zugehörigen Interruptvektors
- d.h. das Herstellen des Anfangszustandes für gewählte Interruptroutine
5. Abarbeitung der Interruptroutine
- Retten weiterer Zustandsinformationen, sofern nicht durch Hardware realisiert
- meistens Übernahme weiterer Parameter von definierten Stellen (bei Systemaufruf Ruf-Nr. und weitere Parameter oder bei Geräte-Interrupt Gerätestatusbits wie E/A Fortschritt, Fehler etc.)
- eigentliche Behandlung des Interrupts, z.B. Setzen eines Flags (z.B. bei Gleitkommaüberlauf oder Aufruf zum Rückpositionieren und erneutem Lesen bei Lesefehler bei Magnetbandkassette (komplizierterer Fall)
6. Rückkehr zur unterbrochenen Aufgabe entweder
- Rückspeichern der geretteten Registerinformationen, d.h. Wiederherstellen des Prozessorzustandes
- oder Bearbeitung einer neuen Aufgabe, z.B. bei Uhrinterrupt nach Ablauf einer Zeitscheibe
- oder Zustand "HALT" nach schwerem Fehler, z.B. Spannungsausfall (abort)
Welche beiden Zustandssicherungskonzepte gibt es
totale Sicherung aller bislang nicht automatisch gesicherten Register
- der CPU-Status des unterbrochenen Programms wird komplett eingefroren
- auch die invarianten Anteile werden gesichert, der Programmzustand ist damit leicht zugreifbar
- weit verbreitet bei Allzweckbetriebssystemen (z.B. UNIX & Co.)
partielle Sicherung der im weiteren Verlauf nicht gesicherten Register
- der CPU-Status des unterbrochenen Programms wird teilweise eingefroren
- es wird nur der wirklich von Änderungen betroffene Anteil gesichert
- der Programmzustand ist damit nicht leicht zugreifbar
- weit verbreitet bei Spezialzweckbetriebssystemen
Was stellt das Hauptproblem bei Interrupts dar
Interrupts verhalten sich nicht deterministisch. D.h. ihre Abarbeitungszeit variiert. Sie sollte trotzdem so gering wie möglich gehalten werden.
Warum wird DMA oft Interrupts vorgezogen?
Zwar befreien Interrupts die Prozessoren vom Warten auf E/A Ereignisse, aber vektorisierte Interrupts benötigen viele Taktzyklen zu ihrer Abarbeitung. Dieser Overhead steigt natürlich, um so weniger Datenmengen bei einer Interruptauslösung übertragen werden. Interrupts werden erst nach der Befehlsabarbeitung erkannt und ausgeführt. Dies ist ein Problem bei Echtzeitanwendungen, da sich diese Verzögerung negativ auswirken kann. Außerdem kommt es durch Interrupts bei Instruction-Set-Parallismus oft zu Pipeline-Neustarts.
Die Lösung dieser Probleme wäre ein direkter Speicherzugriff eines Devices, da so der Prozessor komplett umgangen werden kann.
Wie kann DMA implementiert werden?
| Zentral | Ein zentraler DMA-Controller steht allen Geräten zu Verfügung. |
|---|---|
| Dezentral: | Jede E/A-Einheit hat ihren eigenen DMA-Controller implementiert und kann selbst Busmaster werden |
Probleme bei DMA treten vor allem durch ihre Unabhängigkeit und die dadurch notwendigen Schutzmaßnahmen auf. Ein DMA-Controller wirkt wie ein weiterer Prozessor am Bus. Um Inkonsistenzen im Speicher zu vermeiden, muss ein DMA-Controller eng mit dem Speichermanagment des Systems zusammenarbeiten.
Was ist Memory-Mapped I/O?
Ein I/O Controller besteht aus einer Vielzahl von Registern, welche auf zwei
Varianten adressiert werden können:
Memory-Mapped I/O, um den konventionellen Adressraum verschiedenen
I/O-Devices zuzuordnen oder Getrennten I/O Adressraum, bei dem auf
einer speziellen Adressleitung die E/A-Adresse auf den Bus gelegt wird.
(veraltete Variante)
Was ist eine Task?
Ein Task ist ein eigenständiges Programm / Prozess von vielen im Multitasksystem. Es wird von einem TSS (Task State Segment) beschrieben. Bei einem Taskwechsel werden alle Informationen in diesem TSS gespeichert. Jeder TSS-Deskriptor steht in der GDT. Die GDT hat beim i486 8192 Einträge, jedoch ist der 0. Eintrag immer leer. Somit sind maximal 8191 verschiedene Prozesse möglich (inclusive des Betriebssystems).
Wie werden Task-Wechsel realisiert?
Ein Taskwechsel geschieht durch Auswahl eines Task-Gates aus Globaler Deskriptor Tabelle (Task State Segment = TSS). Ein TSS Enthält alle Informationen, die einen Task ausmachen:
- verwendete Prozessor-Register
- LDT-Selektor (einer Pro Task) welche die Segment-Deskriptoren des Prozesses enthält
- Stack-Segment-Pointer
- Verwaltungsinformation
- Adresse der Paging-Tabellen
- I/O-Map Base Adresse
- Busy-Bit, definiert den aktuell rechnenden Task (genau einer im System)
- enthält den aktuellen TSS (Selektor des Descriptors des aktuellen TSS)
- TSS-Descriptoren nur in GDT!
Umschalten durch jeweiligen Austausch des Back-Link, IRETD zum anderen Task, z.B. Timer-Interrupt-Task.
Welche Möglichkeiten für Privilegwechsel gibt es?
- CALL in eine Prozedur mit anderen Privilegde-Level (CALL-Gate)
- JMP in eine Prozedur mit anderen Privi legde-Level (TASK-Gate)
- INT (TRAP-Gate)
- TASK-Gate durch erzwungenen Prozeßwechsel
- IRET Rücksprung aus INT-Handler
Was ist der Unterschied zwischen einem Selektor und einem Deskriptor?
Ein Selektor Segment-Register wählt einen Deskriptor in (GLI)DT aus, ein Deskriptor Eintrag in (GLI)DT, beschreibt das Segment.
Weshalb ist es sinnvoll, dass ein TSS-Descriptor nur in der GDT stehen darf?
Es soll verhindert werden, daß ein USER-Programm in einen anderen Task springt. Da Taskwechsel nur über TASK-Gates erfolgen (dieses zeigt auf einen TSS-Deskriptor) muß der CurrentPrivilegdeLevel (CPL vom CS:) numerisch kleiner sein, als das des geforderten TSS-Deskriptor (DPL) bzw. kleiner als der (RPL) des Segments wo sich der TSS-Deskriptor aufhält. Damit wird sichergestellt, daß der Taskwechsel nur von "höherem" Code (OS) aus ausgeführt werden kann. Würde ein TSS-Deskriptor in der LDT stehen, könnte es dort mit einem höheren RPL versehen werden, und der USER-Code könnte sich zum OS-CODE etablieren!
Welche Grundtypen von Deskriptoren gibt es?
| IDT | LDT | GDT |
|
CODE-Segment DATA-Segment STACK-Segment |
CODE-Segment DATA-Segment STACK-Segment |
|
|
INT-Gate TRAP-Gate TASK-Gate |
TASK-Gate |
TASK-Gate CALL-Gate |
Welche grundlegenden Adressierungsarten gibt es?
- Unmittelbare Adressierung
- Direktadressierung (Direct Adressing)
- Registeradressierung
- Indirekte Registeradressierung
- Indizierte Adressierung
- Basisindizierte Adressierung
- Stapeladressierung
Unmittelbare Adressierung
- Der Adressteil der Instruktion enthält den Operanden selbst, anstatt eines Verweises.
- Solche Operanden werden als Direktoperanden (Immediate) bezeichnet
- Bsp: MOV R4, 5H (5H wird direkt in R4 gespeichert)
Direktadressierung (Direct Adressing)
- Es wird eine volle Adresse des Operanden angegeben
- Deshalb nur für globale Variablen anwendbar, da Instruktion immer auf gleiche Speicehrzeile zugreift
Registeradressierung
- Das gleiche Prinzip wie Direct Adressing, nur das Register anstelle von Speicherzellen verwendet werden
- In Registern sollten die am häufigsten verwendeten Variablen abgelegt werden, da Register vielfach schneller als Hauptspeicher sind
- Load/Store-Architekturen nutzen fast nur diesen Registermode (außer es muss vom oder zum Speicher transferiert werden)
Indirekte Registeradressierung
- Die Adresse wird nicht direkt angegeben, sondern indirekt über ein Register
- Das Register enthält somit einen Pointer auf eine Speicherzelle
- Vorteil ist, daß auf Speicher referenziert werden kann, aber keine volle Speicheradresse notwendig wird
Indizierte Adressierung
- Der Speicher wird durch Angabe eines Registers und eines konstanten Offsets adressiert
- Häufig benutzt bei Arrayzugriffen, wie A = B[i] (MOV R1, B[R2])
Basisindizierte Adressierung
- Speicheradresse wird hier durch Addition zweier Register und einen optionalen Offset berechnet
- Eines der Register stellt die Basis dar und ein anderes den Index
Stapeladressierung
- Hier ist gar keine Adressangabe notwendig
- Somit sind die Instruktionen sehr kurz
- Die Stapeladressierung arbeitet mit der umgekehrten polnischen Notation (Postfix)
Kapitel 3 - Speicherschutz und Multitasking
Um unberechtigte Zugriffe, Datenaufrufe oder Systemprozedurecalls zu vermeiden und Task-Isolation zu gewährleisten, ist ein ausgeklügeltes Speicherschutzsystem notwendig.
Segmente zum schützen von Speicherbereichen
Segmente sind logische Speicherbereiche variabler Länge (Pages sind normalerweise gleich groß und ergeben zusammengesetzt ein Segment). In einem Segment ist wiederum eine Aufteilung in Code-, Daten- und Speichersegment zu finden. Jedes Segment definiert ein Objekt, welches eindeutig über einen Deskriptor mit Basisadresse, Zugriffsrechten und Limit beschieben wird. Auf Basis dieser Segmente arbeitet die komplette Speicherverwaltung eines Rechners.
Wie wird auf Segmente zugegriffen?
Segmente werden über eine Deskriptortabelle indiziert. Die Tabellen enthalten Pointer auf die Speicherbereiche der jeweiligen Segmente.
Was ist das besondere am segmentierten Adreßraum?
Adressen auf Basis von Segmenten sind im unterschied zu linearen Adressen zweidimensional. Sie bestehen aus Segment und Offset. Berechnet werden sie durch einfache Addition von Segment und Offset. Vor der Addition ist das Segment um 4 Stellen nach links zu verschieben.
0002 : 000F berechnet sich also aus 0020 + 000F = 0001F
Was sind die Nachteile des Realmodes?
- Begrenzung eines Segments auf maximal 64 KB, da Offsetadresse nur 16 Bit groß ist
- Es nur das erste MByte durch das Betriebssystem adressierbar
- kein Schutz des Speichers vor anderen Programmen
- Einträge aus der Interruptvektor-Tabelle sind leicht veränderbar
- nur ein Programm kann ausgeführt werden
Was hat Multitasking mit Protected Mode zu tun?
Multitasking kann nur durch Protected Mode arbeiten. Er ist sozusagen Grundlage für alle multitaskingfähigen Betriebssysteme. nsbesondere geht es um
- gegenseitigen Schutz der laufenden Tasks
- Taskwechselunterstützung durch das Betriebssystem
- Privilegierungsmechanismen
- Betriebssystemfunktionen zur Verwaltung von virtuellen Speicher
- Getrennte Stacks für Parameterübergabe
- Lösung des "Trojanischen Pferd" Problems
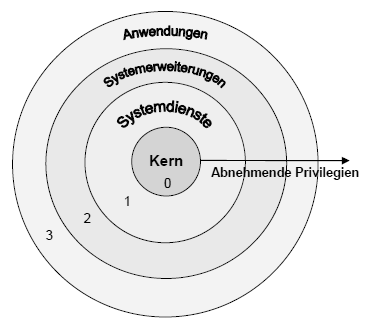
Privilegebenen
Im Protected Mode werden Anwendungen und Betriebssystem strikt getrennt. Es gibt vier Privilegstufen (null bis drei), welche über die Ausführung verschiedener Maschinensprachebefehle entscheiden. Befehle der Ebene Null sind z.B. das Laden der globalen Deskriptorentabelle oder des Maschinenstatuswortes.
Aus welchen beiden Teilen besteht eine Virtuelle Adresse?
Eine virtuelle Adresse beinhaltet den Segmentselektor, welcher auf einen
Eintrag in der Deskriptortabelle zeigt. Das Segment-Offset zeigt auf die
dazugehörige Adresse in dem selektierten Segment.

Aus welchen drei Teilen setzt sich ein Segmentselektor zusammen?
Aus dem Index, der den Eintrag in der Deskriptortabelle referenziert, dem Table Indicator, welcher über globalem oder lokalem Adressraum entscheidet und den Privelege Level.
| TI - Table Indicator | 0 = GDT (Global Deskriptor Table für den globalen Adreßraum) 1 = LDT (Local Deskriptor Table für den lokalen Adreßraum) |
|---|---|
| RPL | Requestor's Privilege Level |
| Privilegstufe | des Segments, auf welches der Selektor verweist |
Was ist ein Deskriptor?
Deskriptoren sind Abbildungen zwischen der virtuellen bzw. logischen Adresse (Segmentselektor:Offset) und der linearen Adresse (Basisadresse und Offset). Aus der linearen Adresse wird dann die physikalische Adresse berechnet. (bei i286 war die lineare Adresse noch gleich der physikalischen Adresse, da es noch keine Paging-Einheit gab)
Was steht alles in so einem Eintrag in der Deskriptortabelle?
Die "normalen" Deskriptoren, welche einen normalen Adressraum (Daten-, Code- oder Stacksegment) beschreiben, enthalten
- die Basisadresse des Segmentes im Speicher
- die Zugriffsrechte
- die Länge des Segmentes
Eine andere Klasse von Deskriptoren sind System-Segment-Deskriptoren und zur Ablaufsteuerung notwendige Deskriptoren. Erstere definieren Einsprungpunkte in spezielle System-Unterroutinen oder Gates. Letztere sind Deskriptoren für Task-State-Segmente oder Local-Deskriptor-Tables.
Aktiv sind aber immer nur eine globale, eine lokale Interrupt-Beschreibertabelle und eine Interrupt-Beschreibertabelle.
Was ist ein Gate?
Gates sind spezielle Eintritts-Deskriptoren in Segmente höherer Privilegstufe. (Interrupt- oder Trap-Gate-Deskriptoren)
Worin unterscheiden sich GDT und LDT?
Die Global Descriptor Table einhält Segmente des globalen Adressraums, welcher für alle Tasks zur Verfügung steht. Dagegen sind mit Local Descriptor Table allokierte Segmente nur von den Host-Tasks selbst adressierbar. (privater Adressraum) Lokale Deskriptortabellen sind Grundlage für die Task-Isolation und daher extrem wichtig für Sicherheit und Segmentschutz.
Beschreiben Sie den Aufbau einer Globalen Deskriptortabelle
| ... | ... |
| Globale C/D2 | Globale Code-/Daten-Deskriptoren |
| Globale C/D1 | Globale Code-/Daten-Deskriptoren |
| ... | ... |
| System D2 | Gates bzw. TSS-Deskriptoren |
| System D1 | Gates bzw. TSS-Deskriptoren |
| ... | ... |
| ... | ... |
| LDT 2 | Lokale Deskriptoren für individuellen Task |
| LDT 1 | Lokale Deskriptoren für individuellen Task |
| ... | ... |
| ... | ... |
| IDT 2 | Interrupt/Exeption Gates bzw. Deskriptoren |
| IDT 1 | Interrupt/Exeption Gates bzw. Deskriptoren |
| GTD_alias | ermöglicht dynamischen Zugriff auf die GDT |
| 0-Selektor | Zugriff auf 0-Selektor führt zu Exeption |
Was unterscheidet Real-Mode und Protected-Mode?
Im Real-Mode gibt es keine Deskriptoren und somit ist auch kein Segmentschutz möglich. Die Basisadresse berechnet sich einfach aus dem Segment-Register, welches maximal 1 MByte adressieren kann, da es nur 20 Bit breit ist. Im Protected-Mode werden die Basisadressen mittels Deskriptoren bestimmt.
Auf Grund dieser Unterschiede sind folgende Merkmale für den Protected-Mode signifikant:
- Virtuelle Speicherverwaltung
- Speicherschutzmechanismen durch Segmentation (über Deskriptoren)
- Paging möglich
- echtes Multitasking möglich
- I/O-Privilegierung und privilegierte Befehle
Was ist Paging und wie funktioniert es?
Paging wird ab i386 vom Prozessor unterstützt und ist nichts weiter als eine Einteilung des Speichers in gleich große Seiten. Vorteil des virtuellen Speichers, welcher durch Mapping oder Paging erst möglich ist, sind für Anwendungen theoretisch unendlich großen Arbeitsspeicher. Grund dafür ist, dass der Tertiärspeicher als Zwischenspeicher für schlafende oder temporär nicht notwendige Seiten ausgenutzt wird. Es gibt ausgeklügelte Seitenerstetzungsalgorithmen, welche das Austauschen von Seiten übernehmen. Ein weiteres Problem was beim Paging gelöst werden muss, ist die eventuell entstehende Inkonsistenz. D ieses Problem wird wie bekanntermaßen üblich durch Dirty-Bits in den Pages gelöst.
Verwirrend ist anfangs der Zusammenhang von Segmentierung und Paging. Letztendlich laufen beide Technologien gleichzeitig auf einem modernen System und ergänzen sich gegenseitig. Paging ist hinter den Segmentierungsvorgang geschalten, um Transparenz zu gewährleisten. Die durch die Segmentierung berechnete bzw. übergebene lineare Adresse entspricht ohne Paging der physikalischen. Falls Paging aktiv ist, muss noch etwas mehr getan werden.
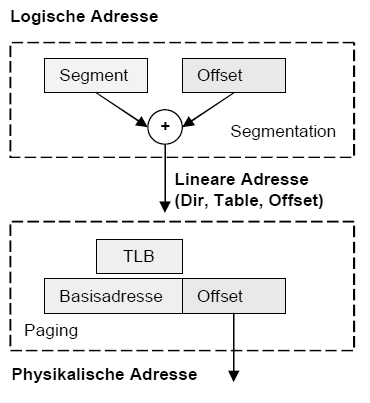
Die Umsetzung von Linearer in Physikalischer Adresse hängt vom verwendeten Paging ab. Normalerweise wird über die ersten Bits die Page-Table referenziert und über die folgenden der Pagetable-Eintrag, aus dem die Basisadresse geholt wird. Der Offset wird normalerweise beibehalten.
Beschreiben Sie was bei einem Page-Fault intern alles abläuft?
- Während Abarbeitung einer Befehlssequenz erfolgen mehrere Seitenzugriffe
- Es erfolgt ein Zugriff auf eine Seite.
- Prozessor prüft die Seite (ist sie im Speicher?).
- Seite gibt Page Not Present State zurück (d.h. Seite nicht im Speicher)
- CPU löst Page Fault Exception aus (Siehe System-Aufruf-Deskriptoren)
- Betriebssystem gibt in Auftrag die Seite von Platte zu holen
- Prozessor aktiviert Festplattenhardware und positioniert Leseköpfe
- Seite wird über DMA-Transfer von Disk-To-free Memory übertragen
- Betriebssystem aktualisiert Pagetable einschließlich des TLB (flush TLB)
- Betriebssystem startet den unterbrochenen Befehl neu
Nennen Sie Vorteile und Nachteile des Pagings gegenüber Segmentation-Only!
- Performanceerhöhung eines Multitasking-Betriebssystems
- Verwaltung der Swap-Datei wird durch die Verwendung konstanter Speicherblöcke einfacher
- nur die 4-KByte werden eingelagert, die tatsächlich benötigt werden und nicht das gesamte Segment
- Ausführung verzögert sich, weil die Adresse erst dekodiert werden muß
- bei Zugriff auf eine Seite/Page evtl. erst Einlagerung dieser vom Sekundärspeicher notwendig (Present-Bit)
Wie kann man die Adressdekodierung beim Paging umgehen?
Durch Translation Lookaside Buffer. Ein TLB ist ein assoziativer Vierwege-Cache, welcher die 32 Page-Table-Einträge aufnimmt, auf die der Prozessor zuletzt zugegriffen hat (LRU-Strategie). Ein TLB Eintrag besteht aus drei logischen Blöcken:
- Datenblock mit Page-Attributen und physikalische Basisadresse einer Page
- Tagblock enthält die oberen 17 Bit einer linearen Adresse und Schutz-Bits
- LRU-Block (Least Recently Used) zeigt letzten Zugriff an
Page- und Segmentschutz
Zuerst wirkt der Segmentschutz und danach Pageschutz. Pageschutz ist nur 2-stufig. Die inneren drei Privilegebenen sind beim Paging als Supervisor-Code geschützt. Die äußere Ebene ist User-Code. Ein Zugriffsversuch einer User-Page auf eine Supervisor-Page löst eine Exception aus.
Was unterscheidet kooperatives und preemtives Multitasking?
Beim kooperativen Multitasking entscheiden die Tasks selbst über die Umschaltung der Prozessorleistung. (Naives und Gutgläubiges Verfahren, daß an die Vernunft aller Tasks und somit aller Programmierer glaubt : ) Preemptives Multitasking ist echtes Multitasking. Ein externer Timer steuert die Umschaltung der Tasks. Die Tasks können somit keinen Einfluss auf die Betriebsmittelumschaltung nehmen.
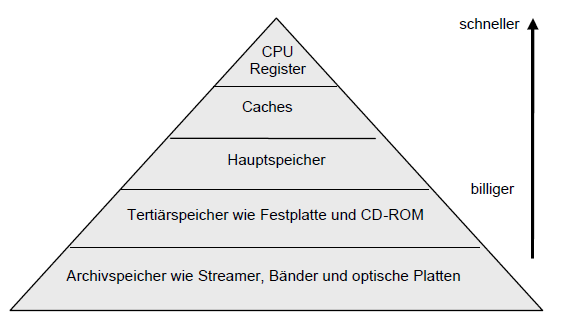
Kapitel 4 - Speicherhierarchie und Caches
Was bedeutet die Eigenschaft Lokalität?
Aus programmtechnischer Sicht wiederholen sich oft Befehle und ganze Programmteile. Somit werden Daten oft wiederholt angefordert. Es gibt nun zwei Arten von Lokalität:
Was ist Zeitliche Lokalität?
Auf ein gerade zugegriffenes Datum wird sicher bald wieder zugegriffen.
Was ist Räumliche Lokalität?
Auf Daten, deren Adressen benachbart sind, wird mit hoher Wahrscheinlichkeit auch zugegriffen. Anzumerken ist, daß Datenzugriffe eine geringere Lokalität zeigen als Befehlszugriffe.
Nach welchen Merkmalen lassen sich Caches klassifizieren?
- Cache-Größe (damit verbundener Hardware-Aufwand)
- Größe einer Cachezeile (Verschmutzungseffekt)
- Cache-Organisation (Vollassoziativ/Direct Mapped/Satz-Assoziativ)
- Schreibstrategie (Write-Through /-Allocate oder -Back)
- Split-Cache-Design (Transfer-Bandbreiten)
- Multi-level Cache-Hierarchien (Workingssetgrößen)
- Effective Working Set (Overflow-, Victim-, Trace Cache)
- Innere Cache-Parallelität (Streaming)
- Kohärenz-Verfahren (Snooping, MESI)
Wie ist ein Cache aufgebaut?
| Zeile 1 | Adress-Tag | Datenblock | Control(Bits) |
| Zeile 2 | Adress-Tag | Datenblock | Control(Bits) |
| Zeile 3 | Adress-Tag | Datenblock | Control(Bits) |
| ... | Adress-Tag | Datenblock | Control(Bits) |
| Zeile n | Adress-Tag | Datenblock | Control(Bits) |
Control-Bits sind z.B. Valid-Bits, Dirty-Bits und Prozess-ID. Das Adress-Tag ist nichts weiter als ein Teil der Adresse, welche bei einem Zugriff als Index gilt. Ein Datenblock ist in der Praxis meistens zwischen 16 und 64 KByte groß.
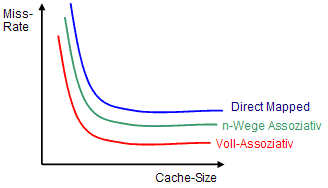
Welche Cache-Arten kennen Sie?
Ein Cache-Eintrag besteht aus einem Tag (Identifikator) und den Daten. Die Implementierung unterscheidet sich. Es gibt voll-, einfach assoziative und Satzassoziative Caches .
Wie arbeitet ein vollassoziativer Cache?
Das Tag Feld ist hier die assoziierende Adresse des Datums im Speicher. Die Hardware ist bei vollassoziativen Caches aufwendig, da diese bei einem Cache Zugriff alle Tags gleichzeitig mit der anliegenden Adresse vergleicht. Dies ist zwar extrem schnell, aber sehr teuer. Außerdem wird er sehr langsam wenn die Anzahl der Cachezeilen hinreichend groß wird.
Da bei vollassoziativen Cachen ein Datum an jede Stelle des Caches platziert werden kann, muss eine Logik her, welche eine Entscheidung trifft. Als Plazierungsstrategie wird oft LRU verwendet. Dies ist seht aufwendig!
Wie arbeitet ein Direct-Mapped-Cache (einfach assoziativer Cache)?
Beim Direct-Mapped-Cache entscheidet eine Map-Funktion,
welche Zeile im Cache mit der anliegenden Adresse referenziert wird (somit ist kein
LRU o.ä. notwendig). Dabei wird einem Hauptspeicherblock genau ein Cache-Block
zugeordnet (n:1 Beziehung). Oft wird eine Funktion wie (A mod Cachesize /
Zeilengröße) zur Berechnung der Cachezeile aus der anliegenden Adresse
benutzt, da bei diesem Verfahren dann nur (A / Cachesize) als Tag in jeder
Cachezeile gespeichert werden muss.
Vorteil dieser Variante ist die einfache, kostengünstige Integration (nur
Komperator notwendig) und die hohe Geschwindigkeit. Leider neigt ein
Direct-Mapped-Cache zu vielen Konflikten (ähnlich den Kollisionen bei Hash-Tables),
welche zusätzliche Cache-Misses bildet, da mehrere Adressen auf die gleiche
Cachezeile verweisen.
Wie arbeitet ein n-Wege-Satz Cache (Satzassoziativer Cache)?
Diese Variante ist nichts anderes als eine Implementation mehrerer parallel
verknüpfter Direct-Mapped-Caches. Sie stellt quasi einen Kompromiss
zwischen Cache-Effizienz und Aufwand dar.
Die Arbeitsweise ist die gleiche, nur das die Map-Funktion nicht nur auf eine Zeile
im Speicher zeigt, sondern auf n. Die Hardware des Caches
vergleicht alle n Tags gleichzeitig, mit dem anliegenden Index.
Ist eine der Tags gleich dem Index, ist dies ein Cache-Hit. Diese Technik reduziert
die hohe Anfälligkeit von Direct-Mapped-Caches für Konflikte, benötigt aber mehr
Chipfläche.
Welche Schreibstrategien für Caches gibt es?
Write-Back,Write-Throug und Write-Allocate.
Write-Back-Strategie?
Ein zu lesendes Datum wird entweder bei einem Hit aus dem Cache gelesen oder im Falle eines Misses, aus dem Hauptspeicher geholt und parallel in den Cache eingetragen. Im Falle der Aktualisierung, muss erst das Dirty-Bit der zu überschreibenden Cache-Line geprüft werden, um diese gegebenenfalls in den Hauptspeicher zurückzuschreiben. (Write-Back)
Vorteil dieser Strategie ist das bei Hits kein Hauptspeicherverkehr oder Busbelastung auftritt. Alle Operationen können schnell innerhalb der Working-Sets mit Cache-Speed erfolgen. Somit arbeitet die CPU ungebremst. Problematisch wird dies, wenn mehrere Bus-Master am Bus hängen. Um Inkonsistenzen zu vermeiden sind dann spezielle Synchronisationsprotololle wie MESI notwendig.
Concurrent Write-Back?
Bei einfachen Write-Back-Caches muss die CPU im Falle eines Cache-Misses warten, bis die neue Cache-Line aus dem Speicher geholt wurde. Um diese Wartezeit im Mittel zu eliminieren, wird die alte Zeile zunächst in einen Writebuffer zwischengespeichert und später, parallel zu nachfolgenden Cache-Referenzen in den Hauptspeicher übernommen. (Sonderform: Buffered Line Refill)
Wenn auch beim Lesen ein Line-(Read)-Buffer verwendet wird, spricht man von einem Streaming Cache.
Write-Through-Strategie?
Write-Through schreibt immer in den Hauptspeicher und falls sich eine Kopie auch im Cache befindet, so wird diese aktualisiert. Genau aus diesem Grund ist kein Rückschreiben eines Dirty-Datums notwendig, da es zu keinen Inkonsistenzen zwischen RAM und Cache kommen kann. Nachteil ist aber, dass nur bei Leseoperationen ein Geschwindigkeitsvorteil erzielt werden kann
Buffered Write-Through
Im Mittel erfolgen nach jeder Write-Operation zwei Read-Operationen. Deshalb kann ein Geschwindigkeitsgewinn erzielt werden, wenn ein schneller Zwischenbuffer (FiFo) vor dem Speicher plaziert wird, welcher einige Write-Operationen aufnehmen kann. Wird nun eine Leseoperation ausgeführt, so kann das Datum falls es noch in dem schnellen Buffer steht, direkt aus diesem gelesen werden.
Write Allocate
Hier wird immer in den Hauptspeicher und in den Cache geschrieben - auch wenn das Datum sich noch nicht im Cache befand.
Zusammenspiel bei Cache-Misses
Write-Allocate wird meistens mit Write-Back Strategie gemeinsam verwendet. Write-Allocate bedeutet dabei nichts weiter, als das der Hauptspeicher-Block in den Cache geladen wird.
Beim No-write-Allocate (Write-Around)
wird das Datum direkt
im Hauptspeicher modifiziert, weshalb Write Around meist
mit Write-Through verbunden wird.
Zusammenfassung Caches
Write-Back wird üblicherweise mit Write-Allocate kombiniert. Beim Write Allocate (fetch-on-write) wird ein Block gelesen und in Cache gespeichert.
Beim No-write-allocate (write-around) wird der Block in der unteren Ebene der Speicherhierarchie modifiziert und nicht nicht im Cache geladen. No-write-allocate wird deshalb meist bei Write-through verwendet.
Was ist der Unterschied zwischen einen logischen und einen physischen Cache?
Physische Caches liegen vor der MMU und speichern somit nur physikalische Adressen. Ein logischer Cache liegt zwischen CPU und MMU und speichert logische Adressen. Vorteil von logischen Caches ist daher, dass die Adressumrechnung bei einem Hit entfällt. Ein großer Nachteil sind aber die Synonym-Probleme bei Multiprozessorsystemen. Des weiteren wird bei Taskwechsel ein Cache-Flush notwendig.
Multi-Level-Caches und Split-Caches
Durch Hintereinanderlegen von verschiedenen Caches kann ein gleitender Übergang zu immer größeren und langsameren Speichern erreicht werden. First Level Caches sind meist n-Wege-Satzassoziativ und folgende Direct-Mapped.
Split-Caches trennen Code und Daten und sind somit viel flexibler und besser an das Zugriffsverhalten in Bezug auf Strategie oder Assoziativität zu optimieren. Dabei unterscheidet man eine Havard-Architektur von der multiplexed Havard-Architektur (von Neumann Prinzip). Die reine Harvard trennt nicht nur Cache sondern auch den Hauptspeicher in Daten und Codebereich. Bei von Neumann liegen Daten und Code zusammen im Hauptspeicher und werden nur im Cache getrennt. Durch Trennung von Code und Daten verdoppelt sich die Bandbreite, da zeitgleich zugegriffen werden kann.
Was geschieht wenn kein Platz mehr im Cache vorhanden ist?
Es muss eine Cache-Line ausgewählt werden, die mit den neuen benötigten Daten überschrieben werden kann. Die Auswahl erfolgt meistens mit LRU - Last Recently Used. D.h. die am längsten nicht genutzte Cache-Line fliegt raus.
Was ist ein Burst-Cache?
Burst Caches schreiben nicht nur eine Zeile in den Speicher zurück, sondern gleich mehrere, um die Bandbreite auszunutzen und somit Zeit zu sparen.
Zusammenhänge zwischen Caches, TLB's und Page Tables
Folgende vier Fragen stellen sich bei Caches, TLB's und auch bei Page Tables:
- Wo kann ein Block eingelagert werden? (Direct Mapped also nur an einem Ort, Set Assoziativ an mehreren Orten oder Voll Assoziativ, also überall)
- Wie kann ein Block gefunden werden? (indexiert, limitierte Suche, komplette Suche oder lookup table wie Page Tables)
- Wie wird ein Block bei einem Miss aktualisiert? (normalerweise über LRU oder random Methoden)
- Wie wird mit Schreiboperationen umgegangen? (Write Through oder Write Back)
Was ist ein Trace-Cache
Ein Trace Cache ist ein spezieller Befehlscache, der "Traces" des aktuellen Programmlauf protokolliert. Dabei speichert jede Zeile einen Trace, welcher typisch mehrere taken branches enthalten kann. Befehlsfolgen, die aufgrund von taken branches (weit) auseinander liegen, werden in kontinuierlicher Folge abgespeichert. Gepaart mit multiple branch prediction können mehrere zusammenhängende Basisblöcke parallel gefetched werden. (ergibt hohe issue rate)
Kapitel 5 - Risc
Wie berechnet sich die Prozessorleistung?
Die Prozessorleistung ist umgekehrt proportional zur Ausführungszeit eines
Algorithmus und wird aus folgenden drei Parametern ermittelt:
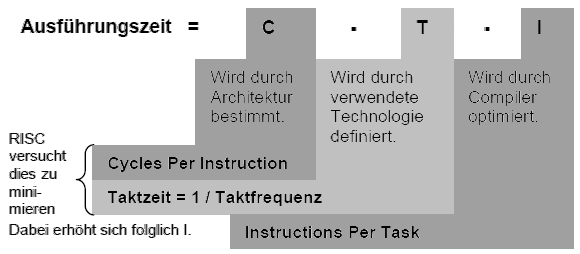
Worum geht es im Besonderen bei einer Risc-Architektur?
RISC Architekturen sind darauf aus, die Cycles Per Instruction zu minimieren. Das heißt, es wird versucht alle Befehle mit so wenig wie möglich Takten auszuführen.
Welche architektonischen Möglichkeiten gibt es zur Veringerung der CPI?
Piplining ergibt eine CPI > 1, andere Techniken wie Superskalarität und
VLIW's haben Ausführungszeiten von kleiner als eins. Kombiniert ergeben beide
Ansätze eine nahezuhe Ausführung von einem Befehl pro Takt.
Desweiteren ermöglicht der kleine Befehlssatz von RISC eine festverdrahtete Steuereinheit, anstatt von Mikroprogrammen, welche höhere Taktzahlen pro Befehl mit sich bringen. Desweiteren muss bei einem Risc-Befehl nicht der Op-Code dekodiert werden, um herauszufinden, wie der Befehl zu entschlüsseln ist, da alle Befehle die gleiche Struktur besitzen.
Auf welche vier Merkmale wird beim RISC-Design-Entwurf besonders geachtet?
- einfache Maschinenbefehle und Adressierungsarten mit einheitlichen Befehlsformat
- große und universelle Registersätze, für schnelle Variablenverarbeitung und größere Optimiermöglichkeiten für Compiler
- Verzahnung von Compiler und Architektur zur Bereitstellung von optimierenden Compilern
- Optimierte VLSI-Chipfläche durch platzsparende Steuerwerke schafft mehr Platz für Optimiertechniken wie Pipelining,Branch-Prediction oder Superskalarität
Techniken zur Ablaufparallelisierung für RISC-Kerne
- Parallelität von einzelnen Befehlsphasen durch Pipelining
- Parallelität von ganzen Befehlen durch Superskalartechnik und VLIW
- Parallelität von Kodefäden durch Multithreading (programmierte Parallelität) oder Multiskalarität (Hardwarethreaderkennung)
- Parallelität von Befehlen unabhängiger Algorithmen (Multiprozessorsysteme)

Pentium 4 Prozessor Kern
Load / Store Architektur und Lokalhalten von Daten
Da Speicherzugriffe in Pipelines starke Konflikte hervorrufen, gibt es bei RISC-Befehlssätzen nur eine einzige Möglichkeit mit LOAD bzw. STORE auf den Speicher zuzugreifen. So werden Registerzugriffe von Speicherzugriffen getrennt. Da Speicherzugriffe bekanntermaßen immer sehr viel Zeit kosten, versucht man diese so weit wie möglich zu vermeiden. Dies Erreicht man durch Lokalhalten von Daten, bzw. das Arbeiten auf den Registern.
Was sind Registerfenster?
Registerfenster sollen das Lokalhalten von Daten unterstützen. Typische RISC Prozessoren wie die Berkeley RISC besitzen weit über 100 Register, von denen aber immer nur 32 für sichtbar sind:
- R0...R9 globale Register
- R10...R15 Ausgaberegister
- R16...R25 lokale Register
- R26...R31 Eingaberegister
Die Idee ist nun, daß die ersten 10 Register von allen Prozeduren gesehen werden. Die Restlichen von R10 bis R31 sind jeweils nur einer Prozedur zugeordnet. Falls nun eine Prozedur eine andere aufruft, wird nur das "Fenster" auf einen freien Registerbereich umgeschaltet. So müssen die Register nicht neu aus dem Speicher geladen werden und es wird dadurch viel Zeit gespart. Normalerweise überlappen sich die einzelnen Fenster um einige Register, um somit gleich eine effiziente Möglichkeit der Parameterweitergabe zu bieten.
Was passiert wenn alle Registerfenster voll sind?
Bei unserem Beispiel mit 138 Registern sind nach sieben Prozeduraufrufen alle Register gefüllt. Um ein Überlaufen zu vermeiden, wird das Register als Ringregister organisiert. Sind alle Registerfenster voll, wird das Älteste in den Speicher ausgelagert, was von sogenannten Trap-Routinen erledigt wird.
Was sind Superpipelines?
Superpipes vereinen Arithmetisches und Befehlspipelining. Arithmetisches
Pipelining ist sogenanntes Funktionspipelining, bei dem einzelne Phasen eines
Befehles in einer Pipeline-Form organisiert werden.
Bei Instruction Pipelining wird die Abarbeitung eines gesamten Befehls in einer
Pipeline organisiert.
Zusammenfassung Risc
- Einfachere Befehlssätze mit ca. 40-80 Befehlstypen
- Einfachere Steuerung durch die Hardware ohne Mikroprogramme
- Effizientere Pipelines durch gleichlange, eintaktige Stufen
- Befehle können meist in einem Takt ausgeführt werden
- Datenzugriffe nur durch Load und Store um Speicherzugriffe zu vermeiden
- Mehr Register und Optimierung des Befehlssatzes durch Compiler
Typische Riscsysteme haben eine hartverdrahtete Steuereinheit und somit keinen Mikrocodespeicher. Der Pentium ist ein "hybrid"-System mit RISC Kern. Dabei werden komplexe CISC Befehle durch ein Mikroprogramm in RISC zerlegt und im Kern ausgeführt. Die einfachen Befehle werden direkt im RISC Kern in einem einzigen Datenzyklus ausgeführt. Alle wichtigen elementaren (Risc) Befehle werden direkt von Level 0 ( der Hardware ) ausgeführt und somit nicht via Mikroinstruktionen interpretiert. Dies ist ein Vorteil von reinen RISC Systemen, welche diese Interpretationsebene zwischen Hardware und ISA (Instruction Set Architecture) Ebene nicht durchlaufen müssen. Mikroinstruktionen steuern den Datenweg für einen Zyklus. Sie enthält alle notwendigen Bit-Belegungen für ALU, MEM, Register etc., um einen Zyklus abarbeiten lassen zu können. Die Adresse der nächsten Mikroinstruktion wird ebenso mit codiert, wie die Art und Weise des Aufrufes. Die Mikroinstruktionen werden in einem Steuerspeicher gehalten, welcher das jeweilige Mikroprogramm enthält. Der Steuerspeicher muss die Mikroinstruktionen nicht in geordneter oder sequentieller Folge enthalten, wie es beim Hauptspeicher der Fall ist. Es kann jede Instruktion einen Verweis auf die Nächste enthalten. Sprünge sind einfach möglich. Angewandt wird dies in Form von Opcodes, welche nichts anderes als Adressen auf Mikroinstruktionen im Steuerspeicher sind.
Kapitel 6 - Pipelining
Wozu dient Pipelining?
Pipelining soll es ermöglichen Befehle überlappt auszuführen. Dazu sind ein einheitliches Befehlsformat fester Länge Grundlage. Deshalb werden werden nur auf Register getätigt. Für Speicheroperationen wird die LOAD / STORE Philosophie verfolgt, um langsame Hauptspeicherzugriffe zu minimieren.
Was ist Voraussetzung für Pipelining?
Die Befehlsverarbeitungsphase muss sich in mehrere voneinander unabhängige Phasen unterteilen lassen. Die einfachste Form einer Pipeline ist die 5-stufige mit folgenden Phasen:
- Befehl holen
- Befehl dekodieren
- Befehl ausführen
- Auf Speicher zugreifen
- Ergebnis in Register schreiben
Moderene CPU's haben weitaus komplexere Pipelines, in denen die einzelnen Stufen wiederrum in mehrere sich überlappende Phasen aufgeteilt werden.
Der allgemeine Aufbau einer (fünfstufigen) Pipeline
Um Parallelität in der Befehlsausführungsphase zu erreichen, wird der Datenpfad so konstruiert, daß folgende (hier fünf) Phasen unabhänig voneinander arbeiten können. Nur so ist es möglich eine verzahnte Abarbeitung mehrerer Befehle zu erreichen.
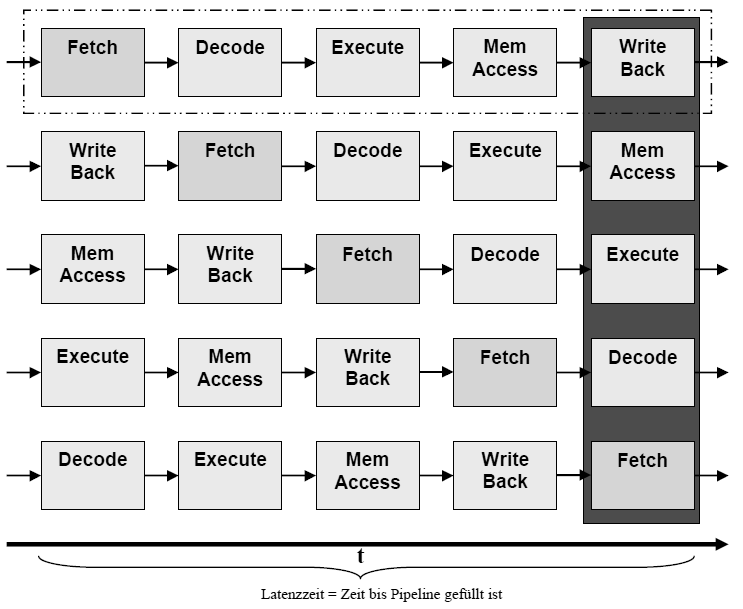
Abb.: Die Piplelinestufen
Somit wird ,nachdem eine Pipeline gefüllt ist, im Optimalfall pro Takt ein Befehl fertig. (CPI = 1)
Welche Pipeline-Konflikte müssen behandelt werden?
Datenabhängigkeiten (Data Hazards)
Sind logische Abhängigkeiten, welche eine verzögerte Abarbeitung erfordern, weil z.B. ein Folgebefehl auf ein Ergebnis eines anderen Befehles warten muss.
Jump- / Branchverzögerungen (Control Hazards)
Bei Sprungbefehlen liegt oft das Sprungziel nach der Dekodieung noch nicht fest. Somit müssen Techniken eingesetzt werden um diese Wartezeiten zu minimieren. (Branch Prediction)
Ressourcenkonflikte (Structural Hazards)
Bei bestimmten Befehlskombinationen ist es unter Umständen möglich, daß ein Teilwerk seine Arbeit wiederholen muss. Solche Ressourcenkonflikte treten dann auf, wenn nicht jeder Teilphase völlig unabhängige Teilwerke zugeordnet sind. Ein Beispiel ist z.B. ein zeitgleicher Lesezugriff eines LOAD/STORE Befehles, welcher sich zwangsweise mit einem eventuellen MEM ACCESS eines anderen Befehles überschneidet.
Abhilfe können hier Dual-Port RAM, Havard-Architektur oder getrennte Code- und Datencaches schaffen.
Welche drei verschiedenen Datenabhängigkeiten gibt es?
RAW, WAW und WAR-Konflikte sind Datenabnhänigkeiten, welche in Pipelines auftreten können. Dabei ist das RAW-Problem für Pipelines typisch. WAR Konflikte treten eher bei Out-Of-Order Execution auf. Um Read-After-Write Konflikte aufzulösen, gibt es verschiedene Ansätze wie Softwarelösungen ( Compileroptimierung), Scoreboarding (zentrale Steuerlogik) und Forwarding (zusätzlicher Datenpfad).
Was ist Forwarding?
Beim Forwarding wird ein Bypass eingerichtet, welcher ein Ergebniss einer Operation schon einem Folgebefehl zur Verfügung stellt, bevor es überhaupt in ein Register geschrieben wurde. Aber trotz Load-Forwarding hat ein Ladebefehl eine Verzögerung, welche nicht gänzlich eliminiert werden kann. In diesem Fall kann die Delayed-Load Technik oder auch eine Befehlsumordnung Anhilfe schaffen.
Was ist die Delayed Load-Technik?
Bei der Delayed Load-Technik wird die Verzögerung nach einem LOAD Befehl als architektonisches Merkmal angesehn und den Compilerbauern offengelegt. Diese können nun durch Befehlsumordnungen versuchen, nach einem LOAD-Befehl einen datenunabhängigen Befehl einzufügen, um den Slot zu füllen.
Zusammenfassung Pipelining
Pipelines werden in allen modernen CPUs benutzt. Die UltraSparc2 hat neun und der P2 zwölf Stufen. Der Intel Pentium Itanium weißt eine 20 stufige Superpinepline (pipeline in der sich einzelne Stufen überlappen können) auf! Pipes werden heutzutage in Kombination mit der Superskalartechnik verwendet, um höchste Effizienz und Parallelverarbeitung gewährleisten zu können. Die fünf grundlegenden Stufen einer einfachen Pipeline sind IF,ID,EX,MEM und WB.
Takte T = Befehle + (Pipestufen - 1)
Folgende Abhängigkeiten verhindern, dass die CPI auf eins gehen:
Strucual Hazards bzw. Ressourcenkonflikte
IF und MEM wollen gleichzeitig auf Speicher lesend oder schreibend zugreifen. Das geht nicht, außer bei Dual-Port-RAM, welcher aber sehr teuer ist. Dieses Problem tritt aber bei modernen CPU's kaum noch auf, da eh intern eine Havard-ähnliche Architektur mit getrenntem Befehls- und Datencache gearbeitet wird.
Data Hazards bzw. Datenabhängigkeiten
Ein Folgebefehl wartet auf das Writeback der darüber liegenden Pipe, da er von diesem Befehl abhängig ist. Dies kann durch Nops bzw. Stalls ineffizient gelöst werden. Besser der Programmierer oder der Compiler löst diese Abhängigkeiten durch eine clevere Umordnung der Befehlsfolge auf. Es gibt aber noch eine andere Möglichkeit, welche aber hardwareseitig unterstützt werden muss. (VLIW, Superskalar)
Forwarding
Beim Forwarding werden Ergebnisse, sobald sie vorliegen an die nächste Stufe weitergereicht und nicht erst auf das Write Back gewartet. In anderen Worten: Das Ergebnis der ALU wird dieser sofort wieder eingespeist.
Control Hazards bzw. Sprungverzögerungen
Sprungergebnisse stehen erst in der Write Back Phase an. Moderne Prozessoren haben aber schon in der Fetch/Decode-Einheit eine Logik, welche die Zieladresse des Sprunges berechnet. Eine andere Möglichkeit ist die des spekulativen Ausführens. Hier tritt aber das Problem auf, dass viel Aufwand bei falscher Spekulation getrieben werden muss.
Was ist der Unterschied zwischen echten und unechten Datenabhängigkeiten?
Echte Datenabhängigkeiten sind RAW-Konflikte, bei dem ein Befehl auf die Beendigung eines Anderen warten muss, da er das Ergebnis als Operand benötigt. Unechte Datenabhängigkeit sind Abhängigkeiten, welche nur durch Namensabhängigkeit entstehen.
Es gibt zwei Arten unechter Datenabhängigkeit:
Antidependence sind WAR-Konflikte, welche entstehen, wenn ein Folgebefehl auf ein Register schreiben möchte, das noch von einem Anderen benutzt wird.
Output Dependece sind WAW-Konflikte, welche entstehen, wenn
mehrere Befehle auf ein und das selbe Register schreiben. Hier muss sichergestellt
werden, daß die Schreibreihenfolge der der Befehle entspricht.
Beide Abhängigkeiten können durch Register Renaming vermindert werden!
Kapitel 7 - Branch Prediction
Control Hazards (Jump / Branch Problematik)
Sprungbefehle stellen einen Dorn im Auge einer jeden Pipeline dar, da diese besondere Vorkehrungen erfordern. Da das Ziel eines Sprungbefehles oft erst festgestellt werden muss, liegt diese Adresse erst ab der MEM ACCESS Phase bereit. Somit kann das erneute Laden des Programmcounters auch erst in dieser Phase geschehen. So verzögert sich das Holen des nächsten Befehles um einige Takte.
Durch eine Optimierung der Pipeline kann zwar die stall-Phase verkleinert, aber nicht ausgeschlossen werden. (durch Verlegung des Sprungbedingungstests in die Decode-Phase)
Welche Methoden gibt es zur Reduzierung von Sprungverlusten?
- Predict Not Taken / Predict-Taken (fixed prediction)
- Objektcode basiert (statisch)
- dynamisch Brach-Prediction mit History Buffern (correlating / non-correlating)
- Delayed-Branch
Wie funktioniert die Predict-Not-Taken bzw. Predict-Taken Methodik?
Hier wird nichts weiter gemacht als entweder alle Sprünge voreingestellt abzulehnen oder alle Sprünge ersteinmal ohne Gewähr duchzuführen. Allgemeine Programmstatistiken sagen aus, dass mehr bedingte Sprünge ausgeführt als abgewiesen werden.
Wie funktioniert die Delayed-Branch Methode?
Hier wird ein sprungunabhängiger Befehl in den Delay Slot eingeschleust. Dies muss somit schon von den Compilerbauern berücksichtigt werden. Um diese Bedingung zu Umgehen wird die "Cancelling Branches"-Technik eingesetzt. Im Mittel werden dann trotzdem die Branch-Verluste verringert. Durch ein zusätzliches Bit im Befehlscode gibt der Compiler die wahrscheinlichste Sprungrichtung an. Nun kann entsprechend dieser Annahme ein Befehl in den Delay Slot eingefügt werden, der nur gültig ist, wenn der Sprung richtig vorhergesagt war. Falls nicht wird der Delay-Slot-Befehl abgebrochen (gecancelt).
Dynamische Branch-Prediction
Um Wartezeiten durch bedingte Sprünge zu vermeiden, sollte das Sprungziel schon mit dem Ende der Fetch-Phase zur Verfügung stehen. Es gibt zwei Ansätze
- Sprungzielspeicher (branch-target-buffer = BTB)
- Sprungvorhersage-Puffer (Branch History Table = BHT)
Wie arbeitet eine Branch History Table?
In dieser Tabelle wird im Grunde nur durch ein Bit (oder mehr) vermerkt, ob ein Sprung durchgeführt wurde oder nicht. Als Index der Tabelle dient der niederwertige Teil der Adresse des dazugehörigen Sprungbefehls. Nun kann die Pipeline in der Fetchphase nach einem eventuell vorhandenen Eintrag schauen und diesen als Entscheidungsgrundlage nehmen.
Welchen Nachteil hat die 1-Bit Sprungvorhersage?
Es wird nicht nur bei einem Schleifenaustritt der Sprung falsch vorhergesagt, sondern auch die erste Vorhersage bei erneuter Verwendung der Schleife.
Wie arbeitet die 2-Bit-Sprungvorhersage mit BHT?
Durch einen einfachen Zähler kann man den Nachteil der 1-Bit-Vorhersage minimieren. Hier wird die Vorhersage erst geändert, wenn sie zweimal falsch war. Es hat sich gezeigt, daß durch Zähler mit mehr als 2 Bit sich die Performance nicht weiter signifikant erhöhen läßt.
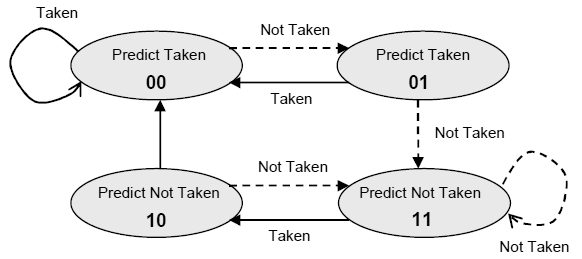
Abb.: 2-Bit-Sprungvorhersagenautomat
Wie arbeitet der Branch-Target-Buffer?
Hier wird die Zieladresse eines gemachten Sprungs direkt gespeichert, um diese gegebenfalls ohne Verzögerung wiederzuverwenden. So kann bei einem Hit (Index stimmt mit Befehlsadresse überein) sofort der Instruction Counter mit der dazugehörigen Sprungadresse geladen werden).
Exeptions
Exeptions unterbrechen den Programmablauf Aufgrund verschiedenster Fehler oder Anforderungen, wie Softwareinterrupts, Page Faults oder anderen Verletzungen. Bei synchronen Exeptions treten die Fehler stehts an der gleichen Programmstelle auf. Asynchrone werden durch externe Geräte ausgelöst und können nach dem laufenden Befehl ausgeführt werden.
Was sind Precice Exeptions?
Sind Exeptions, welche garantieren, dass die Exeptions direkt nach oder während des Befehles ausgeführt werden und kein Folgebefehl vorher abgearbeitet wird.
Zusammenfassung der Sprungvorhersage
Sprungvorhersage ist extrem wichtig für Pipelining und Superskalarität, um stalls und Verzögerungen zu minimieren. Bei statischer Vorhersage werden Rückwärtssprünge meist erst durchgeführt und Vorwärtssprünge nicht. Wurde ein Sprung falsch vorhergesagt, muss die angefangene Instruktion rückgängig gemacht werden, was aufwendig ist. Deshalb gibt es ausgeklügelte Verfahren für die Branch Prediction.
Statische Sprungvorhersage
Es werden Compiler benutzt, die spezielle Sprungbefehle mitführen, welche ein Bit für die Sprungvorhersage enthalten. Da der Compiler ja weiß, wie oft eine Schleife durchlaufen wird, ist das sehr effizient. Dies muss aber architektonisch von der Hardware unterstützt werden. Des Weiteren ist kein Speicher für die History Table notwendig, was es kostengünstiger macht. Statische Verfahren erreichen eine Trefferrate von 65 bis 85%, was für moderne CPU's mit Superpipelines zu wenig ist. Dynamische Verfahren erreichen Trefferraten bei der Vorhersage von 98% und mehr!
Dynamische Sprungvorhersage
Es gibt zwei grundlegende Methoden. BHT und BTB. Die Branch History Table (Branch Predicion Buffer) ist ein Cache, in der alle bedingten Sprünge protokolliert werden. ( bis zu mehereren Tausend) Einfachste Version enthält ein Valid-Bit (Branch taken oder nicht), welches durch den niederwertigen Teil der Sprungadresse adressiert wird. Kompliziere Implementationen arbeiten nach dem n-Wege Prinzip. Durch Second Chance kann dieses Verfahren noch verbessert werden. Der Branch Target Buffer speichert nicht nur die taken-Bits, sondern auch die Sprungzieladresse, um null Verluste bei wiederholtem Aufruf zu haben. Das setzt voraus, dass nur taken branches aufgenommen werden. Bei einem Hit in der BTB kann somit während der Fetch Phase der Program Counter überschrieben werden. Werden keine History Bits mitgeführt spricht man vom BTAB.
Wie arbeitet Second Chance?
Nach Beenden einer Schleife wird ein Sprung logischerweise falsch vorhergesagt. Um zu vermeiden, dass nun fälschlicherweise das Sprungbit falsch gesetzt wird (da ja die gleiche Schleife noch mal durchlaufen werden kann), ändert man dieses erst nach der zweiten falschen Vorhersage. Leicht zu implementieren als Finite State Machine mit vier Zuständen. Nachteil der dynamischen Vorhersage ist die notwendige teuere und komplexere Hardware.
Was ist der Vorteil von BHT gegenüber BTB?
Branch Target Buffer loggen nur, ob ein Sprung genommen wurde oder nicht.
Daher gibt es bei MIPS-Architekturen die BTB verwenden immernoch die sogenannten
Branch Delay Slots, da die Sprungadresse trotzdem neu ermittelt werden muss.
BHT beseitigen diesen Nachteil, da sie die Sprungadresse mit abspeichern und diese
dann sofort in den IP geladen werden kann.
Was sind Correlating Predictors?
Betrachten wir folgendes Codefragment, fällt uns auf, daß ein Branch Predictor, der nur einen Sprung als Entscheidungsgrundlage einbezieht, den Zusammenhang der drei Sprünge nicht erkennen kann.
if (a==10) //1. Sprung
a=0;
if (b=0) //2. Sprung
b=0;
if (a!=b){ //3. Sprung
... //abhängig von 1. und 2. Sprung
}
Um diese Abhängigkeiten in eine Sprungvorhersage einbeziehen zu können, sind Correlating Predictors notwendig. Solche Einheiten werden oft als (m,n)-Predictors bezeichnet.
- protokolliert wird das Verhalten der letzten m Sprünge je mit einem n-Bit Predictor (z.B. 2-Bit Second Chance)
- somit wird aus 2^m*n-Bit Preticors ausgewählt, um Vorhersage für den jeweiligen Sprung zu treffen
Wie werden Correlating Predictors hardwaremäßig implementiert?
Das Implementieren dieser Predictors ist weitaus einfacher, als man es annehmen würde. Es wird einfach für die History-Bits ein m-Bit-Shift Register verwendet, um die letzten m Sprünge zu speichern.
Welche Performancesteigerung ist durch Correlating Predictors erreichbar?
Eqntott ist ein Benchmark, welches speziell mehrere voneinander abhängige Sprünge simuliert. Hier sinkt die Fehlvorhersage von 20% auf unter 8%!
Beim GCC-Compiler sind dagegen keine Unterschiede zwischen Correlating Predictors und normaler 2-Bit Sprungvorhersage erkennbar.
Kapitel 8 - Superskalarität
Was bedeutet superskalar?
Mit normalen Pipelines (Überlappen von Instruktionen) ist nur eine maximale Performance von einem Befehl / Takt technisch und theoretisch möglich. Um diese Grenze zu unterschreiten, ist Parallelität auf Befehlsebene (Instruction Level Parallelism) notwendig. Dies bedeutet das der typische Risc-Prozessor, um Einiges erweitert werden muss:
- Prozessor muss in der Lage sein, mehrere Befehle gleichzeitig pro Takt zu laden
- Branches dürfen möglichst nicht zur Behinderung des Befehlsflusses führen (deshalb Sprungvorhersage)
- Datenabhängigkeiten treten hier in erhöhtem Maße auf und müssen behandelbar sein
- um echte Datenabhängigkeiten auflösen zu können, is Out-Of-Order Ausführung mit anschließender "Sortierung" notwendig
Dynamic Scheduling
Static Scheduling nutzt lediglich Compilertechniken zur Separierung unabhängiger Befehle und ist sehr unflexibel. Beim Dynamic Scheduling wird durch Präsenz mehrerer paralleler Buffer und Execution Units versucht, Ressourcen- und Datenkonflikte zu eliminieren.
Out-Of-Order Execution
In-Order-Issue Pipes müssen, falls ein Befehle gestoppt wird, alle Folgebefehle warten. Durch eine zusätzliche Hardware, welche das Umordnen der Befehlsausführung zur Laufzeit vornimmt, kann dies verhindert werden. Möglichkeiten dafür sind Scoreboards oder Tomasulo.
Was ist das Problem des Präzisen Zustandes?
Das Prinzip des Präzisen Zustandes besagt, daß bei Unterbrechungen (Interrupts, Exeptions) der Zustand der CPU sicherbar und wiederherstellbar sein muss. Dieses Konzept muss auch bei superskalaren Architekturen gelten. Dies ist in superskalaren Architekturen weitaus aufwendiger und bedarf zusätzlicher Hardware.
Welche Entwurfskriterien sind zu betrachten?
- Stategien zum holen mehrerer Instruktionen pro Takt (und Einfluss von Branches)
- Methoden zum Auffinden von Datenabhängigkeiten zwischen Registerinhalten
- Methoden zum Aussenden (Issue) mehrerer Befehle gleichzeitig
- Ressourcen zur paralellen Ausführung (mehrere Ausführungseinheiten und Zwischenbuffer)
- Ausführung mehrerer LOAD/STORE-Pipelines in enger Abstimmung mit Ausführungseinheiten (LOAD/STORE Instruktionen müssen entkoppelt auf Grund der verschiedenen Latenzzeiten ablaufen können)
- Methoden zur Bestimmung der korrekten Ausführungsreihenfolge und Speicherfolge der Register
Superskalar-Prozessoren und VLIW-Prozessoren als Multipe-Issue CPU's
Beide Techniken senden mehr als nur einen Befehl pro Taktzyklus aus und versuchen so, die CPI unter eins zu drücken. Moderne Prozessoren kombinieren beide Techniken. Der größte Unterschied zwischen beiden Technologien besteht darin, daß Very Long Instruction Word basierende Systeme für verschiedene Prozessoren neu compiliert werden muss. Superskalare-Prozessoren sind dagegen gleich kompatibel.
Was heißt Multiple-Issu?
Ist das Mehrfach-Aussenden von Befehlen, welchen gewissen issue criteria unterliegen müssen. Die folgende Abbildung zeigt das Superskalarprinzip - eine 5-stufige Pipeline mit zweifacher Superskalarität.
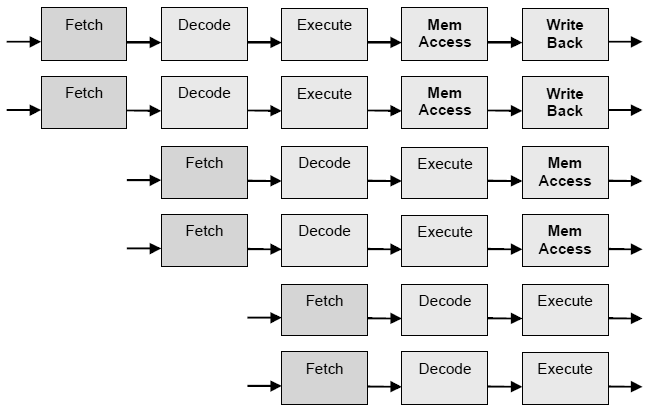
Abb.: zweifach superskalare fünfstufige Pipeline
Superskalarität mit VLIW
Der IA-64-Befehlssatz von Intel wird auf "Very Long Instruction Words" basieren. Es werden drei Instruktionen ein einen fetten 128 Bit Befehl gepackt. Hier besteht nun die Möglichkeit, explizit festzulegen, welche Befehle parallel abgearbeitet werden sollen bzw. können. So eröffnen sich völlig neue Optimierungsmöglichkeiten im Compilerbau. Man nennt dieses Prinzip EPIC. Der Transmeta verwendet auch VLIW. Hier muss aber der Compiler nicht die Optimierungen vornehmen, da der Transmeta um der Core eine Morphing Softwareebene hat, welche die Aufteilung in parallel abarbeitbare Befehle ausführt. Dadurch, daß nun explizit gesagt wird, welche Instruktionen parallel ausführbar sind, ist nun nicht mehr so viel Chipfläche zum Auflösen von Hazards notwendig und kann z.B. für mehr Register verwendet werden.
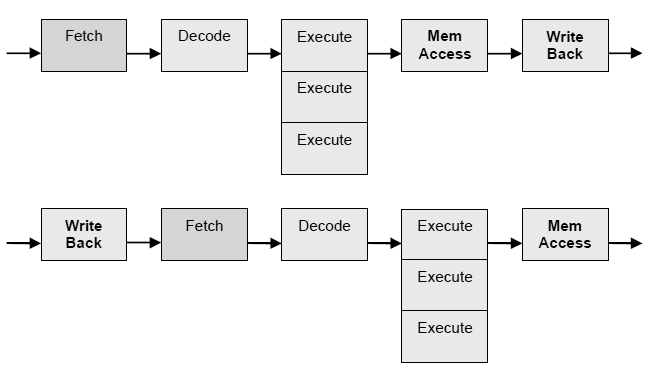
Abb.: Prinzip VLIW mit drei Superbefehlen
Das Scoreboard
Ein Scoreboard ist eine zusätzliche Steuereinheit, welche die Verantwortung für das Befehlsaussenden und das Erkennen von Konflikten trägt. Das Scoreboard wählt aus einem Pool potentiel ausführbarer Befehle (Instruction Window) einen Satz von Befehlen aus. Ein Register wird als ungültig markiert, wenn die Dekodiereinheit erkannt hat, dass ein Befehl sein Ergebnis in dieses Register schreiben möchte. So wird verhindert, dass ein anderer Befehl dieses Register liest, solange es ungültig ist. Nachteil ist, daß keine Ressourcen- und auch keine Datenabhängigkeiten auftreten dürfen. Eine bessere Variante ist die Tomasulo-Methode, welche eine Auflösung von WAR- und WAW-Konflikten ermöglicht.
Zusammenfassend gesagt, besteht ein Scoreboard aus einer Vielzahl von Zählern (wie oft wurde gelesen und geschrieben) für die verwendeten Register und Funktionseinheiten. Ein Scoreboard, welches auch WAR und WAW Konflikte lösen kann, wäre zwar extrem aufwendig aber möglich.
Wann können Befehle mit der Scoreboard Technik nicht ausgesandt werden?
- Wenn ein aktueller Operand geschrieben wird (RAW)
- Wenn das Ergebnisregister gelesen wird (WAR)
- Wenn das Ergebnisregister geschrieben wird (WAW)
WAR und WAW sind weniger schwerwiegend als RAW Abhängigkeiten, da diese nur Ressourcenkonflikte darstellen. RAW Konflikte logische Abhängigkeiten und können nicht so einfach aufgelöst werden. Mit der Scoreboard Methode muss gewartet werden, bis der abhängige Vorgängerbefehl sein Ergebnis geschrieben hat. Erst dann kann der Folgebefehl das benötigte Datum lesen und mit der Abarbeitung fortsetzen. Lösen lassen sich alle Probleme mit Out-Of-Order Execution und Register Renaming Technik. Dazu muss das Scoreboard erweitert werden.
Die Tomasulo-Methode
Hauptidee sind hier sogenannte Reservation Stations, welche eine Art Zwischenpuffer für Operanden darstellen. Die Reservation Stations besitzen eine eindeutige ID, welche jedem Befehl mitgegeben wird. So kann die richtige Reihenfolge beibehalten werden. Wird ein Befehl ausgeführt, arbeitet dieser nicht auf den eigentlichen Registern, sondern auf den assoziierten Reservation Stations, was das Prinzip des schon erwähnten Register Renamings ist. Über einen Common Data Bus werden die Ergebnisse zu allen beteiligten Einheiten gebroadcaset. Reservation Stations erkennen Hazards und können selbst entscheiden, wann sie den dazugehörigen Befehl ausführen. Nämlich erst dann, wenn alle Operanden vorliegen. Um controll stalls komplett vermeiden zu können, wird die Tomasulo-Methode mit der spekulativen Befehlsausführung kombiniert.
Wie arbeitet die spekulative Befehlsausführung?
Sprungziel-Befehle werden schon ausgeführt, wenn das Ergebnis des Sprungtests noch gar nicht vorliegt. Somit muss es die Möglichkeit geben, bei falscher Vorhersage alle Änderungen zu Verwerfen (Rollback-Fähigkeit). Die Hauptsächliche Hardware-Erweiterung liegt in der Aufspaltung der Ergebnisschreibphase in eine Bereitstellungsphase mit Zwischenspeicherung im Reorder Buffer und eine Phase in der ein Befehl commited, d.h. gänzlich der Ausführung übergeben wird. Ein commit bedeutet, daß eine eventuelle Sprungvorhersage richtig war! Somit stellt dies eine Kombination von out-of-order-execution via Tomasulo mit einem erzwungenen in-order-commit dar.
Der Reorder-Buffer stellt in der Welt des Tomasulo weitere Register zur Verfügung, welche auch die Funktion von Store Buffern übernehmen könnten, so daß dieser als Teil des Tomasulo nicht direkt mehr erkennbar wäre. (Store Buffer enthalten Informationen darüber, welche Reservation Stations, welches Ergebnis erwartet)
Aus welchen Feldern setzt sich ein Reorder-Buffer-Eintrag zusammen?
- Befehlstyp (Branch, Store oder Registeroperaton)
- Zielfeld (Registernummer oder Speicheradresse)
- Datenfeld (Ergebnis der Operation)
Die Phasen des Tomasulo
| Fetch und Decode |
Holt Instruktionen in einen Befehlscache. Die Decode-Unit holt sich einen
Teil der Befehle und versucht mehrere gleichzeitig zu decodieren
(In-Order). Dabei wird versucht Sprünge vorherzusagen. Übergibt dekodierten Befehle in der richtigen Reihenfolge an die Dispatch (Issue) Unit. |
| Dispatch / Issue | Holt dekodierte Befehle aus Befehlspuffer und übergibt sie In-Order an die Reservation Stations der Execute Units, sobald alle Operanden verfügbar sind (Issue). Solange im Reorder Buffer Platz ist, reserviert sie ein Feld für diesen Befehl mit Hilfe des Tags und gibt dieses an die RS weiter. Wenn nicht wartet sie, bis ein Platz frei wird. (Dispatch Phase) |
| Execution |
Führt Befehle auf den Schattenregistern aus, um Data Hazards zu meiden. Befehle werden in den Reorder-Buffer geschrieben und Out-Of-Order ausgeführt, solange es keine RAW-Konflikte gibt. Nach Beenden eines Befehls wird Ergebnis an alle RS gebroadcastet, so dass wartende Befehle fortfahren können. (Write result) |
| Commit | Die Commit/Completion oder Retire Einheit schreibt die Ergebnisse aus den Renaming Registern in die echten ISA Register zurück, nachdem sie geprüft hat, ob abhängige vorangehende Befehle ihre Ergebnisse geliefert haben und keine falsche Sprungvorhersage eingetreten war. |
Erklären Sie die Phasen Issue, Execute, Write Result und Commit!

Die Issue-Phase entnimmt einen Befehl aus dem Befehlsbuffer und versucht diesen an eine freie Reservation Station zu übergeben. Dabei reserviert sie einen Platz im Reorder-Buffer und gibt den dazugehörigen Tag an die Reservation Station. So kann beim Ergebnis-Broadcasting das Ergebnis mit diesem Tag gekennzeichnet werden. (1)
Sind nun alle notwendigen Operanden vorhanden und keine weiteren RAW-Abhängigkeiten bestehen, kann der Befehl ausgeführt werden. (Execute-Phase). (2)
Ist das Ergebniss berechnet, wird es auf den CDB gelegt und in den Reorder-Buffer geschrieben (Write Result). (3)
Der Reorder-Buffer ist als Ringbuffer angelegt, bei dem die Reihenfolge der Befehle, durch die der erwarteten Ergebnisse (über das verliehene Tag) definiert wird. Nun werden in der Commit-Phase falsch vorhergesagte Sprünge zurückgesetzt und es wird bei dem richtigen Nachfolgebefehl fortgesetzt. Das Ergeniss wird in die ISA Register zurückgeschrieben. (4)
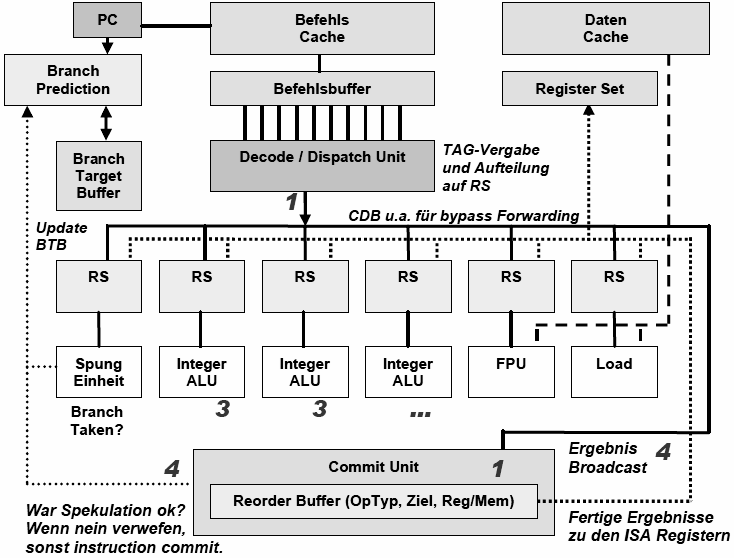
Abb.: abstrahierter RIST-Kern eines Pentium Pro / Power PC
Muliple Issue am Beispiel
Instruktionen werden in eine oder mehrere Mikrooperationen dekodiert und in eine Warteschlange gestellt. Sprungerkennung erfolgt erst statisch und dann dynamisch mit 4 History Bits (da siebenstufige Decode-Pipeline!). Dann werden Register im Reorder-Buffer (der P4 hat Platz für 40 µOps) zugewiesen. Dabei werden um Konflikte zu vermeiden Renaming-Register (Schattenregister) eingesetzt. In der Execute Phase werden Mikrooperationen aus dem Reorderbuffer entnommen und spekulativ ausgeführt.
Es wird ein komplexes Scoreboard verwendet, um aktive Operationen und Register zu verwalten. Falls mehrere Mikrooperationen bereit sind, wählt ein Algorithmus den nächst Wichtigsten aus (z.B. Sprünge).
Mikrooperationen deren Operanden alle verfügbar sind, werden in die Reservation Stations geschrieben, welche 20 solcher Einträge aufnehmen kann. Dort warten die Ops, bis eine entsprechende Ausführungseinheit frei wird.
Die Execute-Units haben fünf Ports, um Operationen auszuführen. Manche Ausführungseinheiten teilen sich einen Port (FPU,MMX).
Die Retire (Completion) Einheit sendet fertige Ergebnisse an die richtige Stelle. Der P2 unterstützt speculative execution. Falls begonnene Instruktionen nicht mehr benötigt werden, wird die Rollback Fähigkeit genutzt.
Der Pentium 4 nutzt einen Trace Cache für die letzten drei dekodierten Befehle. Im Hit Falle, bedient sich die Execution Unit direkt dieser Befehle, was vor allem bei Schleifen einen beträchtlichen Speedup bringt.
Die UlraSparc 2 ist dagegen eine reine Risc Maschine mit vierfachen statt 2facher Superskalarität. Durch das Risc Prinzip müssen hier Instruktionen nicht in mehrere Mikrooperationen umgesetzt werden. Desweiteren unterstützt die meist gleich große Befehlslänge das Pipelining besser, als die z.T. komplexeren Cisc Befehle des Pentium.
Neu ist das so genannte Folding der PicoJava CPU, welche Instruktionen faltet, d.h. zusammenfasst und gleiche Instruktionen in einem Zyklus (auf verschiedenen Regstern) abarbeiten kann. ( 5 x schneller als P2, obwohl auch CISC)
Superskalarität
- Auflösung von RAW durch Out-Of-Order Ausführung möglich
- WAW und WAR Konflikte durch Register Renaming auflösbar
- Tomasulo liegt Idee der Reservation Stations zu Grunde
- Tomasulo wird zusammen mit Spekulativer Ausführung angewandt
- Meist vier Phasen, wie Fetch/Decode, Issue, Execute und Commit
Wie werden Unterbrechungsanforderungen gehandhabt?
Bei Interrupts muss sichergestellt werden, daß nach Abarbeitung der Unterbrechung, die CPU wieder in einen sicheren (präzisen) Zustand zurückkehren kann.
Das erste Verfahren benutzt Checkpoints, an denen der tatsächliche Zustand der CPU ein Update erfährt und der bisherige in einen History-Buffer gelegt wird. Somit ist jederzeit ein präziser Zustand wiederherstellbar (Recovery), wobei innerhalb der Commit-Phase nur der korrekte Zustand hergestellt werden muss und die nicht weiter benötigten aus dem Historybuffer wieder entfernt werden.
Das zweite Verfahren wird dem Ersten oft bevorzugt. Es steht eng mit der Verwendung des Reorder-Buffers in Verbindung. Dabei wird der Zustand des Rechners in zwei aufgeteilt:
- einen Physikalischen Zustand, der bei jeder ausgeführten Instruktion gesetzt wird
- und einem architekturellen Zustand, welcher erst beschrieben wird, wenn ein eventueller spekulativer Status geklärt wurde
Während der Commit-Phase, wird der spekulative Zustand in den architekturellen (und den physikalischen) übernommen, die Renaming Register des Reorder-Buffers in die Registerfile geschrieben bzw. die Store-Operation durchgeführt. Dabei wird der "spekulative Zustand" ebenfalls im Reorder-Buffer mitgeloggt.
Zusammenfassung Superskalar-CPU's - dynamic scheduled pinelines
Da das Pipeline Konzept schnell an seine Grenzen gelangt ist, ist eine andere Methode notwendig. Es muss möglich sein, dass mehrere Befehle pro Takt beendet werden können und unabhängige Befehle, welche in Pipes wegen vorangehender Abhängigkeiten warten müssen, in der Ausführungsfolge vorzuziehen. Superskalare Prozessoren erkennen parallel verarbeitbare Befehle von selbst und benötigen somit keine speziell optimierenden Compiler, wie sie z.B. VLIW verlangen. Dafür sind sie weitaus komplexer. Um RAW, WAW und WAR Abhängigkeiten zu vermeiden, wird versucht Instruktionen anders anzuordnen. Dafür ist ein Scoreboard notwendig, das für jedes benutzte Register die Leseabhängigkeiten und Schreibabhängigkeiten zählt.
Der Tomasulo Algorithmus ist ein Verfahren, welches sich durchgesetzt hat, da es WAW und WAR Konflikte dynamisch auflösen kann. Dies ist so einfach möglich weil WAW und WAR keine echten Datenabhängigkeiten sind, sondern nur entstehen, wenn ein späterer Befehl ein Register wiederverwendet, ohne die darin enthaltenen Daten zu benötigen.
Hier tritt das Register Renaming oder "Arbeiten auf Schattenregistern" in Kraft. Würde es mehr Register geben, könnten diese Abhängigkeiten schon vom Compiler aufgelöst werden.
Mit Register Renaming werden intern versteckte Register benutzt, um Abhängigkeiten aufzulösen.
Spekulative Ausführung wird benutzt um weitere Lücken im Ablauf zu füllen. Hierbei werden Sprungziel-Befehle gegebenenfalls schon ausgeführt, wenn noch gar nicht klar ist, ob dieser überhaupt wahr werden. Dies wird meist mit dynamischen Scheduling nach Tomasulo kombiniert. Falsch vorhergesagte Befehle erreichen nie die Commit-Phase und werden verworfen. Dies ist möglich, da sich die Ereignis-Schreibphase in Bypassing (Zwischenspeicherung im Reorder-Buffer) und dem Rückschreiben auf die echten ISA Register aufteilen lässt.
Wie können RAW-Konflikte gelöst werden?
RAW Konflikte sind echte Abhängigkeiten und gekönnen nicht aufgelöst werden. Es kann nur Versucht werden, durch eine Out-Of-Order Ausführung die Ausführungseinheiten stets gefüllt zu halten, um somit negative Auswirkungen auf den Befehlsfluss zu minimieren oder zu vermeiden.
Kapitel 9 - Parallelrechner
Wie kann man Parallelrechner klassifizieren?
In SIMD (Single Instruction Multiple Data) wie Array-Rechner und MIMD (Muliple Instruction Multiple Data), wie
- MPP - Massive Parallel Processor System
- VC - Vector Processor (Paralleliät durch Pipeline)
- PVP - Parallel Vector Processor
- Cluster (COW) - Uniprocessor, SMP
- NOW - Network Of Workstations
- Grid - Metacomputer (Cluster von vernetzten homogenen Parallelrechnern)
In der Implementation wird zwischen MIMD-Systemem mit gemeinsamen oder globalen Speicher und synchronen oder asynchronen Systemen unterschieden.
Was ist ein Cluster
"Form einer parallelen Rechnerarchitektur, die auf einem Ensemble von unabhängigen Computern beruht, welche durch ein Verbindungsnetzwerk zu einem koordinierten System zusammengefasst werden, um gemeinsam an einer Aufgabe arbeiten zu können."
Was unterscheidet Cluster von MPP (Massiv Parallel Processors)?
Ein Cluster basiert auf COTS-Komponenten und stellt einen Knoten mit vollständigem Betriebssystem dar:
- Knoten als Single Node nutz- und kontrollierbar
- gewöhnte vollständige Ablaufumgebung(bekannte Konzepte, Compiler, Tools usw.)
- Multi-tasking und potentiell Multi-User fähig
- Paging, BS Protection
- Betriebssystem liefert die Kommunikations-Abstraktion
- Stand-alone, d.h. kein Front-end Rechner nötig
Was ist ein Grid
Computational Grid ist eine Form eines parallel-verteilten Systems. Es basiert auf dem Zusammenschluß regionaler, nationaler und globaler (heterogener) Rechner, Daten ,Grafiken und Embedded Ressourcen durch ein Hochleistungs-Kommunikationsnetz.
Grids werden zur Bildung übergeordneter verteilter Verbundsysteme (Metacomputer) mit Leistungen im Tera-scale Bereich benutzt. Grids werden immer in Verbindung mit einer entsprechenden (Grid)Software- Infrastruktur und Zugangssoftware(Grid-Portale) genutzt.
Was ist der Unterschied zwischen symmetrischen und asymmetrischen MPs?
Bei asymmetrischen Systemem gibt es einen Master-Prozessor, welcher an das I/O Subsystem gekoppelt ist. Restliche Prozessoren sind Slaves und sind nicht direkt mit dem I/O Subsystem verbunden. Daher können die Slaves auch nur Anwenderkode ausführen. Zur Ausführung von Systemdiensten muss der Master gerufen werden, da nur er Betriebssystemoperationen ausführen darf.
Bei symmetrischen Systemem liegt das Kernel-Image für alle Prozessoren erreichbar im Shared Memory. Das I/O Subsystem und Interrupts können parallel von mehreren Prozessoren bearbeitet werden.
Was besagt die Klassifikation nach Flynn?
| Instruktionsströme | Datenströme | Bezeichner | Typische Anwendungsfälle |
| 1 | 1 | SISD | Von-Neumann Rechner |
| 1 | N | SIMD | Vektorrechner |
| N | 1 | MISD | (noch) nicht existent |
| N | N | MIMD | Mehrprozessor und -rechner |
Worin liegt der signifikante Unterschied zwischen SIMD und MIMD Systemen?
SIMD Systeme benutzen zwar getrennte Datenspeicher, bekommen ihre Befehle aber aus einem globalem Befehlsspeicher. Bei MIMD Systemen hat jede Einheit seinen eigenen Befehlsspeicher.
Was macht ein Shared Memory Sytem (Mehrprozessorsystem) aus?
Alle CPU's teilen sich gemeinsamen Speicher. Deshalb ist Kommunikation hier besonders einfach. Ist jede CPU gleichberechtigt und austauschbar, wird das System SMP genannt. Nachteile sind, daß dieses Prinzip nur bei kleinen Prozessorzahlen überschaubar bleibt und das das Prinzip nicht skaliert.
Was ist Distributed Memory? (Mehrrechnersystem)
Diese Systeme definieren sich dadurch, dass jede CPU ihren eigenen Speicher besitzt. Kommunikation erfolgt hier über ein Verbindungsnetz, was Mehrrechnersysteme weitaus komplizierter macht, als Multiprozessorsysteme. Eine Möglichkeit des gemeinsamen Speichers ist Distributed Shared Memory. Hier stellt das Betriebssystem den systemweiten Adressraum als gemeinsamen Speicher zur Verfügung. Der Vorteil ist, dass LOAD und STORE Befehle auf fremde Speicher möglich sind. Es wird sozusagen die Seitenersetzung nicht von der Festplatte, sondern vom entfernten Rechner vollzogen. Kommunikation erfolgt mit Hilfe von Eingangs- und Ausgangspuffern an den jeweiligen Maschinen durch das Message Passing.
Was bedeutet UMA - Uniform Memory Architektur?
Es gibt entweder einen globalen Bus mit einem einzigen physischen Speicher
oder einen globaler Speicher, bestehend aus mehreren Teilen, die parallel
zugreifbar sind (besser skalierbar).
Hinsichtlich der Zugriffgeschwindigkeit sind beide Lösungen "uniform", d.h. es gibt
keine Unterschiede abhängig davon, auf welchen Teil des Globalspeichers zugegriffen
wird = Uniform Memory Architektur (UMA)
Was sind Non-Uniform Memory Architecture Systeme?
Hier geht es um Systeme die auf Distributed Shareded Memory basieren. D.h. die Rechner können gegenseitig auf den Speicher anderer Rechner zugreifen. Der Zugriff auf lokale und entfernte Speicherteile erfolgt mit unterschiedlicher Geschwindigkeit. Deshalb Non-Uniform Memory Architecture (NUMA).
Routing von Paketen im Mehrrechnersystem
Wie die einzelnen Pakete vom Sender zum Empfänger gelangen, bestimmt das Routing. Es ist ebenso dafür verantwortlich Deadlocks zu vermeiden. Dabei sind die Prozesse die Rechner und die Betriebsmittel die Ein - und Ausgabeports der jeweiligen Stationen.
Was ist ein Vektorrechner?
Viele numerische Probleme lassen sich auf Skalarprozessoren nur in vielen Schleifendurchlaufen berechnen. Vektorcomputer bieten high level instructions, um diese Schleife mit einem Befehl zu berechnen. Pipelines bieten sich mehr als an. Da die Datenelemente unabhängig sind, treten keine Data Hazards auf und das Fehlen von Schleifensprungbefehlen lässt keine Control Hazards in der Pipeline zu. Um die Speicherbandbreite zu erhöhen, verwendet man das Prinzip der Speicherverschränkung. Caches haben wenig Effizienz, da Vektorprobleme geringe Lokalität aufweisen. Die Bandbreite wird durch Blockzugriff und zeitlich verschränkten Speicherbankzugriff maximiert. (memory interleaving und memory banking)
Was unterscheidet die Hardware eines Vektorrechners von Konventionellen?
Die Register sind nicht eindimensional sondern bestehen aus Vektoren. D.h. das ein Registersatz 2-Dimensional ist. Sämtliche Hardwarekomponenten sind somit auf die Verarbeitung von Vektoren, anstatt einzelner Worter ausgelegt.
Wie arbeitet Speicherverschränkung?
Der der Hauptspeicher wird in gleichgroße, voneinander unabhängige Bereiche (Module, Speicherbänke) unterteilt, die zeitlich verschränkt gelesen oder beschrieben werden können. Aufeinanderfolgende Speicherworte werden zyklisch in aufeinanderfolgenden Speicherbänken abgespeichert. Sinn macht das Ganze wegen der Diskrepanz zwischen Zugriffs- und Zykluszeit der Hauptspeichermodule. Während die Zugriffszeit jene Zeit angibt, die zum Lesen bzw. Schreiben eines Speicherwortes benötigt wird, beschreibt die Zykluszeit eines Speichers die Zeitspanne vom Beginn eines Zugriffs bis zu jenem Zeitpunkt, zu dem der nächste Zugriff beginnen kann. Daß Zugriffs- und Zykluszeit für Hauptspeichermodule nicht übereinstimmen, liegt daran, daß sich der Speicher nach einem Zugriff zunächst regenerieren muß, bevor er neue Zugriffe erlaubt. Für gängige Halbleiterbauteile ist die Zykluszeit eines Speichers etwa drei- bis viermal so groß wie dessen Zugriffszeit. Für den Durchsatz eines nichtverschränkten Speichers ist dessen Zykluszeit und nicht die Zugriffszeit ausschlaggebend. Bei einem verschränkten Speicher ist, wenn auf die verschiedenen Module in geeigneter Reihenfolge zugegriffen wird, für den Durchsatz die deutlich kürzere Zugriffszeit sowie die Anzahl der Module entscheidend. Die größte Beschleunigung der mittleren Zugriffszeit wird erreicht, wenn aufeinanderfolgende Speicherzugriffe auf verschiedene Module erfolgen.
Interleaved Memory bei Vektorrechnern
Da Speicher zu langsam, werden nun mehrere unabhängige Speicherbänke realisiert, von denen jeder einen bestimmten Teil des Adressraums zugesprochen bekommt. Beziehen sich aufeinander folgende Speicherzugriffe jeweils auf Adressen verschiedener Speicherbänke, können die Folgezugriffe überlappt werden. Bis 512 Speicherbänke sind durchaus normal, um diese Latenzzeiten der DRAMs zu minimieren. Um Speicherbankko nflikte zu vermeiden, müssen Programmablauf und Speicherimage aufeinander abgestimmt sein. Dabei wird der Vorteil genutzt, dass die Position von aufeinander folgenden Vektorelementen im Speicher nicht sequentiell sein muss. Wie bei Pipelines wird hier die Forwarding-Ähnliche Technik des Chainings angewandt, um Resultatelemente einer Vektoroperation sofort an den Folgebefehl weiterzuleiten, ohne auf das Fertigstellen des Befehls zu warten. Unter Nutzung mehrerer Funktionseinheiten können Vektoroperationen damit quasi parallel ausgeführt werden.
Worauf muss ein Programmierer bei Interleaved Memory achten?
Der Programmablauf muss auf das Speicherabbild abgestimmt sein, das keine Konflikte auftreten können. Konflikte treten auf, wenn bspw. durch eine ungünstige Schleifenvariante immer die gleiche Speicherbank angesprochen wird und somit eine starke Verzögerung eintritt. Die Schleife sollte so aufgebaut sein, dass die Bandbreite komplett ausgenutzt werden kann.
Was definiert im Besonderm die Leistung eines Vektorrechners?
Die Leistung berechnet sich vor allem aus der Vektorlänge. Umso größer die verarbeiteten Vektoren sind, umso höher die Leistung. Da bei Vektorrechnern die StartUp-Zeit beträchtlichen Einfluss hat, sind hohe Performance-Werte nur bei ausreichend gefüllten Vektoren zu erreichen. Pauschal kann man sagen, dass ein Vektor mindestens halb gefüllt sein muss, um parallesierbare Programme ausreichend Effizient abarbeiten zu können.
Wie arbeiten Bus-basierte Multiprozessorsysteme?
Hier arbeiten mehrere CPU's in einem System parallel. Dabei hat jeder Prozessor gleichen Zugriff zum zum Hauptspeicher über einen Systembus, welcher von allen Prozessoren genutzt wird. (Shared Memory) Logische Konsequenz ist, daß die Speicherbandbreite proportional zu der Anzahl N der Prozessoren sinkt. (1/N) Dieser Flaschenhals wird durch Caches vermindert. Solange ein Prozessor im Mittel N Zugriffe im Cache und erst dann einen im Hauptspeicher tätigt, wirkt diese Bandbreitenbegrenzung noch nicht negativ. Da die Lokalität von Programmen nunmal auch begrenzt ist, sind soclche Multiprozessorsysteme höchstens bis um die 30 Prozessoren skalierbar.
Kann sich die Leistung eines SMP-Systems überproportional steigern (bei 4 CPU's 5-fache Leistung)?
Ja, dass kann genau dann passieren, wenn die benötigten Daten im Singlesystem nicht in den Cache passen. So kann es unter Umständen bei cleverer Programmierung passieren, daß die Daten verteilt in die vier Caches der vier CPU's passen und somit die Leistung überproportional erhöht werden kann.
Wie wird der Bus verteilt (Arbitierung)?
Zentral oder dezentral mit Test & Set Befehlen.Zentrale Arbiterlogik
Die Master senden einen Bus-Request an die zentrale Abiterlogik. Diese entscheidet, welcher Prozessor das acknowlege-Signal und somit den Bus zugesprochen bekommt.
Dezentral - Daisy Chained Prinzip
Die Priorität der einzelnen Master ist durch Ihre Reihenfolge implizit gegeben. Ein BusGrant Signal wird durchgeschleift und kann, wenn es benötigt wird, durch einen Bus-Request an die Zentrale aktiviert werden. Dieses Verfahren ist äußerst ungerecht.
Test & Set Befehle und Bus-Arbitierung
Test & Set Befehle sind atomare Befehle zum Synchronisieren von Prozessen. In Uni-Prozessorsystemem ist das Problem der "Zerissenen Befehle" dadurch gelöst. Anders bei Multiprozessorystemen. Dort kann es nach wie vor passieren, dass der aktive Prozessor den Bus entzogen bekommt und somit eine laufende Test & Set Instruction unterbrochen würde. Deshalb ist hier ein zusätzlicher Mechanismus notwendig. Es wird ein Lock-Signal eingeführt, welches dem Bus-Arbiter ein Umschalten zwischen einer Read- und Write-Phase eines Test & Set Befehls verhindert.
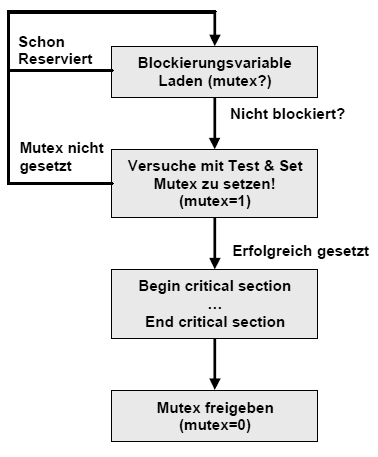
Abb.: Test and Set Protokoll für Mutual Exclustion
Cache-Kohärenz-Protokolle
Write-Through (Keine Inkonsistenz wegen Durchschreiben) und Write-Back (verringert Speicherverkehr, aber ermöglicht Inkonsistenten) sind die wichtigsten Methoden auf Singleprozessorsystemem. Write-Throung ist das einfachste und Write-Back das effizienteste, welches in Form des MESI-Protokoll z.B. im Pentium angewendet wird. Bei SMP's dominieren Write Invalidate (alle anderen Kopien werden ungültig gemacht) und Write Broadcast (alle Kopien werden bei Schreibaktion aktualisiert) als Vertreter der Snooping-Protokolle. Ein anderes Snooping Protokoll ist das Write Once-Protokoll.
MESI-Protokoll für Multiprozessorsysteme
Ein Cache Eintrag kann einen von vier verschiedenen Zuständen besitzen. Treten Zustandswechsel auf, werden alle Prozessoren benachrichtigt.- Invalid (die Cacheline ist veraltet)
- Shared (mehrere Prozessoren haben die aktuelle Cacheline)
- Exklusive (Prozessor hat die korrekte Cacheline alleine)
- Modified (Die Cacheline ist aktuell, aber nicht mehr mit Speicher konsistent)
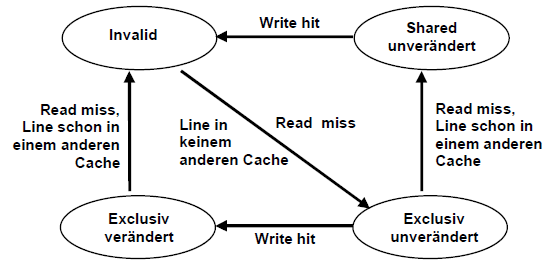
Abb.: Das MESI-Protokoll
Welche drei wesentlichen parallelen Programmiermodelle gibt es?
- Message-passing Programmiermodell
- Shared-memory Programmiermodell
- Data parallel Programmiermodell
Wie arbeitet Message-passing?
Die Prozesse einer parallelen Applikation haben je ihren eigenen privaten Adreßbereich und tauschen sich Daten über explizite Messages aus. Die Synchronisation ist implizit im Akt des Message-Austausches enthalten. Die Programme sind im allgemeinen in einer Single-Program, Multiple-Data- (SPMD) Stream-Struktur geschrieben. Programmierstandards werden de facto durch MPI und PVM gesetzt.
Wie arbeitet das Shared-memory Programmiermodell?
Die Prozesse können hier auf einen gemeinsamen Adreßraum zugreifen. Die Prozeßsynchronisation muß explizit auf der Basis spezieller Synchronisationskonstrukte erfolgen. Als Programmierstandard setzt sich zunehmend OpenMP durch.
Wie funktioniert das Data parallel Modell?
Dieses Modell wird durch eine Data Parallel-Sprache wie FORTRAN unterstützt.
Geschrieben werden die Programme unter Nutzung sequentiellen FORTRANs, um die
Berechnungen auf den Daten zu spezifizieren, wobei sowohl iterative Konstrukte als
auch Vektoroperationen von FORTRAN90 geliefert werden.
Daten-Mapping Direktiven werden verwendet, um die Verteilung von Arrays über
verteilte Prozesse zu spezifizieren.
Nennen Sie die drei Parallelrechner-Rechenprinzipien!
| Von Neumann | Steuerfluß-gesteuert | Operationen werden entsprechend der gesetzten Befehlsfolge ausgeführt |
| Datenfluß | Datenfluß-gesteuert | Operationen werden ausgeführt, sobald die dazu benötigten Daten verfügbar sind |
| Reduktion | Funktionsaufruf-gesteuert | Hierarchisch verschachtelte Funktionen werden von der Hierarchie-spitze nach unten aufgelöst |
Quellen
Andrew S. Tanenbaum
Computerarchitektur
Andrew S. Tanenbaum
Moderne Betriebssysteme
Petterson
Computer Architectur & Design
Christian Märtin
Rechnerarchitekturen
Rehm
Skript und Vorlesung