Künstliche Intelligenz
Einleitung zum Fachgebiet der Künstlichen Intelligenz.
Kapitel 1 - Intelligente Agenten und Problemtypen
Was macht einen "idealen rationalen Agenten" aus?
Er wählt für jede Wahrnehmungsfolge immer den optimalen nächsten Schritt. Die Festlegung dieser Aktionen (Agentenentwurf) ist eine ideale Abbildung von Wahrnehmungsfolgen auf Aktionen. Der Agent kann auf eingebauten Wissen über seine Umgebung und/oder seiner Erfahrung beruhen.
Was bedeutet eigentlich rational in Bezug auf Agenten?
Dies kann nur für einen bestimmten Zeitpunkt beschrieben werden. Vier Merkmale sind dafür maßgebend:
- Das Performancemaß, das den Grad des Erfolges definiert.
- All das, was der Agent wahrgenommen hat (Wahrnehmungsfolge).
- Das was der Agent über die Umgebung weiß.
- Und die Aktionen, die der Agent ausführen kann.
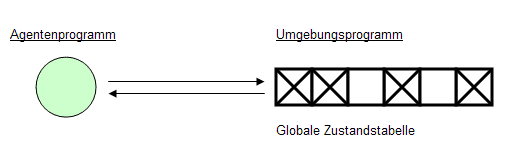
Was ist ein Agentenprogramm?
Ist eine Funktion, welche die Abbildung von Wahrnehmungsfolgen auf Aktionen implementiert. Die Recheneinheit, auf der das Programm läuft, wird Architektur genannt. Diese stellt über Sensoren Informationen zur Verfügung und überträgt die gewählten Aktionen auf die Effektoren.
Nachteile von Lookup-Programmen sind die extrem langen Tabellen und der hohe Zeitaufwand. Es herrscht außerdem keinerlei Autonomie (Erfahrungsabhängigkeit) und somit Unflexibilität bei Umweltänderungen. Selbst wenn der Agent Lernfähig wäre, müßte er stetig Einträge für seine Tabelle lernen.
Unterschied zwischen reflexiven und beobachtenden Agenten
| reflexiv | beobachtend |
|---|---|
|
der Agent erfasst Daten aus seiner Umwelt der Agent hat keinen Gedächtnisspeicher |
der Agent benutzt internen Zustand, um zu entscheiden dieser wird von der Umwelt strukturiert, bleibt ihr aber verborgen |
Was sind einfache Reaktive Agenten?
Einfache reaktive Agenten werden auch als Reflexive Agenten bezeichnet. "Wenn das Auto vor uns bremst, dann leite Bremsvorgang ein." einfache reaktive Agenten reagieren also nur auf spzielle Beobachtungen. Sie haben kein Gedächtnis und müssen daher oft Zufallsentscheidungen treffen.
Worin bestehen beobachtende Agenten?
Diese Agenten beobachten ihre Umwelt und arbeiten somit mit einer adaptivierten Bewertungsfunktion. So kommt es zu einer regelmäßigen Aktualisierung des internen Zustandes. Sie benötigen Informationen, wie sich die Umwelt unabhängig vom Agenten verändert und entwickelt. Agenten die die Welt beobachten sind auch reflexive Agenten.
Was sind Zielbasierte Agenten?
Um im Falle unterschiedlich möglicher Folgezustände die richtige zu wählen, benötigt der zielbasierte Agent Informationen über Ziele. Der Agent vergleicht diese Information mit dem möglichem Ergebnis und wählt so die optimale Aktion aus. Dies ist meist nicht mit einem Schritt sinnvoll möglich, sondern nur mit mehreren Ermittlung solcher Aktionsfolgen über Suchen und Planen.
Nutzenbasierte Agenten
Der Nutzen ist eine Abbildung der Menge der Zustände in die reellen Zahlen. Die zugeordnete Zahl beschreibt, wie günstig der Zustand für den Agenten ist. Um ein Ziel zu erreichen, kann der Nutzen auf zwei Arten verwendet werden:
- Wenn es Ziele gibt, die einen Konflikt bilden, läßt sich mit Nutzen Trade-off bestimmen
- Wenn es mehrere erstrebenswerte Ziele gibt, läßt sich mit Hilfe des Nutzens die Wahrscheinlichkeit des Erreichens eines Ziels gegen seine Wichtigkeit abwiegen
Ein Nutzenbasierter Agent muss auch Zielbasiert sein, da laut Definition dieser mehrere Ziele hat und zwischen den verschiedenen Ebenen wechseln kann.
Welche Eigenschaften definieren Umgebungen?
Zugänglich - Unzugänglich
Eine Umgebung ist zugänglich, wenn der Agent über seine Sensoren alle Informationen aus der Umwelt erfahren kann, die für die korrekte Ausführung seiner Aktionen notwendig sind.
Deterministisch - indeterministisch
Eine Umgebung ist deterministisch, wenn der nächste Zustand vollständig durch den aktuellen Zustand und den gewählten Aktionen definiert ist.
Episodisch - nicht episodisch
Eine Umgebung ist episodisch, wenn sich die Erfahrungen des Agenten in unabhängige Episoden aufteilen lassen.
Statisch - dynamisch
Eine Umgebung ist dynamisch, wenn sie sich ändern kann, während der Agent noch am "denken" ist. Semidynamisch bedeutet nur, dass die Ausführungszeit der Aktionen beschränkt ist.
Diskret - kontinuierlich
Eine Umgebung heißt diskret, wenn es in ihr eine begrenzte und unterscheidbare Anzahl von Wahrnehmungen und Aktionen gibt.
Was sind Umgebungsprogramme?
Sie stellen eine Simulationsumgebung dar, mit der Agentenprogramme getestet werden können. Der Simulator nimmt einen oder mehrere Agenten als Eingabe und stellt den Agenten die richtigen Wahrnehmungen zur Verfügung. Der Simulator nimmt die Aktionen des Agenten entgegen und aktualisiert gegebenenfalls die Umgebung. Eine Umgebung ist bestimmt durch ihren Anfangszustand und ihre Update-Funktion.
Problemformulierung und Problemtypen
Was sind Problemlösende Agenten?
Die Zielformulierung, ausgehend von der aktuellen Situation, ist der erste Schritt beim Problemlösen. Ein Ziel wird als eine Menge von Weltzuständen betrachtet, in denen das Ziel erfüllt ist. Aktionen werden als Übergänge zwischen Weltzuständen betrachtet. Bei der Problemformulierung wird entschieden, welche Aktionen und welche Zustände betrachtet werden sollen. Sie folgt nach der Zielformulierung. Hat ein Agent mehrere mögliche Aktionen mit unbekannten Ausgang, kann er eine Entscheidung herbeiführen, indem er verschiedene mögliche Aktionsfolgen, die zu dem gewünschten Zustand führen, untersucht und die Optimale heraussucht.
- Dieser Vorgang heißt Suche
- Problembeschreibung als Eingabe und Aktionsfolge als Ausgabe
- Die Lösung kann dann in der Ausführungsphase ausgeführt werden
Was gehört zur Problemformulierung?
Um ein Problem formulieren zu können, müssen Zustände bekannt und Aktionen definiert werden. Dafür gibt es verschiedene Problemtypen.
Welche Problemtypen gibt es?
- Ein-Zustands-Probem
- Mehr-Zustands-Probem
- Kontingenz-Problem
- Explorations-Problem
Was ist ein Ein-Zustands-Probem?
Der Agent weiß, in welchem Zustand er sich befindet (d.h. die Umgebung zugänglich) und was jede Aktion bewirkt. So kann er ausgehend von seinem Zustand, für eine Aktionsfolge vorausberechnen, in welchem Zustand er sich nach der Ausführung der Aktionen befinden wird.
Was wird zur Definition eines Ein-Zustand-Problems benötigt?
- Ein Anfangszustand
- Eine Menge möglicher Aktionen
- Ein Zielprädikat
- Eine Pfadkostenfunktion
Was ist ein Mehr-Zustands-Probem?
Der Agent weiß >nicht, in welchem Zustand er sich befindet (Umgebung unzugänglich), aber er weiß was jede Aktion bewirkt. Dann kann er trotzdem das Erreichen eines Zielzustandes vorausberechnen. Dazu muß er aber über eine Menge von Zuständen schlußfolgern und nicht nur über Einen.
Was ist ein Kontingenz-Problem?
Der Agent kann nicht im voraus eine bestimmte Aktionsfolge berechnen, die zu einem Zielzustand führt. Er benötigt während der Ausführung von Aktionen Sensorinformationen, um zu entscheiden, welche der Aktionen zum Ziel führt.
Statt einer Folge von Aktionen braucht er also einen Baum, in dem jeder Zweig von der Wurzel zu einem Blatt eine Aktionsfolge darstellt. Jede Aktionsfolge behandelt ein kontingentes Ereignis.
Was ist ein Explorations-Problem
Der Agent kennt die Auswirkungen seiner Aktionen nicht. Deshalb muß er experimentieren, um herauszufinden, was die Aktionen bewirken und welche Art von Zuständen es gibt. Dies kann er nur in der realen Welt tun. Dabei kann er aber lernen, d.h. eine interne Repräsentation der Welt aufbauen und zur Entscheidungsfindung nutzen. Eine Umgebung für so ein Problem zeichnet sich durch eine dynamische Umwelt aus. Desweiteren müssen die Aktionen Freiheitsgrade besitzen, um so näher an die reale Umwelt heranzureichen.
Kennt der Agent seinen Anfangszustand nicht oder hat dieser mehr als einen
Zustand, kann es kein Einzustandsproblem sein. Benötigt der Agent
Sensorinformationen, um schrittweise zu einem Ziel zu gelangen, kann es auch
kein Mehrzustandsproblem sein.
Somit bleiben Kontigenz- und Explorationsproblem. Ein Kontignenzproblem
besitzt ein festes Repertoire an Funktionen, deren Effekte eindeutig
definiert sind. Ein Explorationsproblem zeichnet sich dadurch aus, daß sich
der Agent vergangene Schritte merkt, aber sich nicht über die Auswirkungen
seiner Aktionen bewußt ist.
Was ist der Anfangszustand?
Der Anfangszustand ist der Zustand, von dem der Agent weiß, dass er sich in Ihm befindet. Eine Aktion wird als Operator oder Nachfolgefunktion bezeichnet, in Verbindung mit dem Zustand, zu dem sie von einem Gegebenen aus führt.
Was gehört zum Zustandsraum?
Der Anfangszustand und die Menge der Aktionen definieren den Zustandsraum. Er besteht aus einer Menge aller Zustände, die vom Anfangszustand aus durch bestimmt Aktionsfolgen, erreichbar sind.
Was ist ein Pfad im Zustandsraum?
Ein Pfad im Zustandsraum ist einfach nur eine Aktionsfolge, die von einem Zustand in einen Anderen führt. Das Zielprädikat kann der Agent auf einen Zustand anwenden, um zu Prüfen, ob e dieser ein Zielzustand ist. Die Pfadkostenfunktion ordnet jedem Pfad im Zustandsraum einen Kostenwert zu. Dieser ist die Summe der Kosten der einzelnen Aktionen entlang eines Pfades.
Was beinhaltet der Datentyp "Problem"?
Der Datentyp Problem ist also definiert durch Anfangszustand, Operatoren, Zielprädikat und Pfadkostenfunktion. Instanzen dieses Datentyps bilden die Eingaben für Suchalgorithmen. Die Ausgabe einer Suche ist dann eine Lösung, d.h. ein Pfad von einem Ausgangszustand in einen Zustand, welcher das Zielprädikat erfüllt.
Wie sind Zustände im Mehrzustandsproblem definiert?
Beim Mehrzustandsproblem werden Zustände durch Zustandsmengen und Aktionen durch Operatormengen ersetzt, welche die Folgezustandsmenge spezifizieren. Ein Operator wird auf eine Zustandsmenge angewandt, indem er auf jeden einzelnen Zustand angewendet wird und die Ergebnisse vereinigt werden. Anstelle des Ergebnisraumes erhält man somit einen Ergebnismengenraum.
Aus welchen Merkmalen wird die Performance einer Problemlösung angegeben?
- Wird eine Lösung gefunden?
- Wie hoch sind die Pfadkosten?
- Wie hoch sind die Suchkosten?
- Die Gesamtkosten sind die Summe aus Pfad- und Suchkosten.
Welche Typen gehören zum Beispielproblem des "8-Puzzle"?
Zustände
Beschreibung der Plazierung aller acht Plättchen sowie der Leerstelle.Operatoren
Bewegung der Leerstelle nach links, rechts, oben oder unten.Zielprädikat
Zustand mit gewünschter Plazierung der Plättchen.Pfadkosten
Jeder Schritt hat Kosten von 1. Die Kosten eines Pfades sind somit gleich der Pfadlänge.Kapitel 2 - Problemlösen durch Suchen
Die fünft Typen der Datenstruktur eines "Knoten eines Suchbaums"
- Der Zustand des Zustandsraums, dem v entspricht
- Der Knoten der v erzeugt hat, also der Vater von v
- Der zur Erzeugung von v verwendete Operator bzw. Aktion
- Die Zahl der Knoten von der Wurzel zu v, was der Tiefe entspricht
- Die Pfadkosten des Pfades vom Anfangszustand bis zu dem v entsprechendem Zustand
Der Rand der Suche und dessen Operationen
Zusätzlich zum Suchbaum wird eine Datenstruktur benötigt, um zwar schon erzeugte, aber noch nicht expandierte Knoten zu speichern. Diese Menge heißt Rand und wird als Liste implementiert und hat folgende Operationen:
- Make-List - Erzeugt eine Liste aus gegebenen Elementen
- Emtpy - prüft ob Liste leer ist
- Remove-Front - entfernt erste Element aus Liste
- Listing-FN - fügt eine Menge von Elementen in die Liste ein. Für das Einfügen gibt es verschiedene Möglichkeiten, welche auch die verschiedenen Varianten von Suchalgorithmen darstellen
Der allgemeine Suchalgorithmus?
Function Allgemeine Suche(Problem,Listing-FN) return Solution or Error; Nodes = Make-List (Make-Node(Initial-State[Problem])); Loop do If (Empty(nodes)) return Error; Node = Remove-Front(nodes); If (State(node)== Zielprädikat[problem]) return node; Nodes=Listing-FN(nodes,Expand(node,Operators[Problem])) End
Nennen sie alle blinden Suchverfahren?
- Breitensuche
- Kostengesteuerte Breitensuche
- Tiefensuche
- Tiefenbegrenzte Suche
- Suche mit iterativen Vertiefen
- Bidirektionale Suche
Die Breitensuche BFS
Realisiert wird BFS über die allgemeine Suche mit einer Listenfunktion mit Tail-Insert. BFS ist vollständig, denn sie findet immer die Lösung, falls diese existiert. Außerdem findet BFS immer die Lösung mit dem kürzesten Pfad. Falls die Pfadkosten eine monoton wachsende Funktion der Tiefe des Suchbaums ist, dann ist BFS sogar optimal. Bei einem Verzweigungsfaktor von b und einer Tiefe von d liegt der Zeit- und Speicheraufwand von BFS bei O(b^d).
| Optimalität: | ja |
| Vollständigkeit: | ja |
| Zeitaufwand : | O(b^m) |
| Speicherplatzbedarf: | O(b^m) |
Die kostengesteuerte Breitensuche
Es wird immer der Knoten als nächster aus dem Rand expandiert, der die geringsten Pfadkosten besitzt. Unter Bestimmten Voraussetzungen wird so eine kostengünstige Lösung gefunden. Die kostengesteuerte BFS findet die kostengünstigste Lösung, wenn sich die Kosten entlang eines Pfades an keiner Stelle verringern.
| Optimalität: | ja |
| Vollständigkeit: | ja |
| Zeitaufwand : | O(b^m) |
| Speicherplatzbedarf: | O(b^m) |
Die Tiefensuche
- Allgemeine Suche mit Listenfunktion mit Head-Insert
- Expandiert immer den Knoten auf der tiefstmöglichen Ebene
- Speicherplatzaufwand ist linear b*m (m ist größte im Suchbaum vorliegende Tiefe)
- Zeitbedarf ist O(bm), da im worst case alle Knoten expandiert werden müssen
- Nachteil der Tiefensuche ist, dass sie in unendlichen Zweigen "hängen bleibt"
- Deshalb ist auch nicht garantiert, dass die Tiefensuche eine optimale Lösung findet
- Tiefensuche ist weder vollständig noch optimal
| Optimalität: | nein |
| Vollständigkeit: | nein |
| Zeitaufwand : | O(b^m) (worst Case) |
| Speicherplatzbedarf: | O(b*m) |
Die tiefenbegrenzte Suche
Es wird die allgemeine Suche mit Operatoren, welche Tiefe kontrollieren implementiert. Zeitbedarf ist dann O(bl), wenn l die begrenzte Tiefe darstellt.
| Optimalität: | nein |
| Vollständigkeit: | nein |
| Zeitaufwand : | O(b^l) |
| Speicherplatzbedarf: | O(b*l) |
Die Suche mit iterativem Vertiefen
Dies stellt eine tiefenbegrenzte Suche dar, welche iterativ mehrere Tiefenschnitte anwendet, um zu einem Ergebnis zu kommen.
- Dieses Verfahren vereinigt die Vorteile der Breitensuche mit der der Tiefensuche
- Sie ist vollständig und optimal
- Die Suche mit iterativem Vertiefen ist das beste blinde Suchverfahren, da es auch auf große Suchbäume mit unbekannter Tiefe anwendbar ist.
| Optimalität: | ja |
| Vollständigkeit: | ja |
| Zeitaufwand : | O(b^d) |
| Speicherplatzbedarf: | O(b*d) |
Die bidirektionale Suche
Bei diesem Verfahren wird simultan vom Ausgangszustand vorwärts und vom Zielzustand rückwärts gesucht, bis sich die beiden Suchpfade in der Mitte treffen. Mit einem Verzweigungsfaktor b und einer Lösungstiefe d ist O(2b^d/2)=O(b^d/2). Folgende Voraussetzungen müssen gegeben sein:
- Vorgänger eines Knotens muss erzeugbar sein
- Alle Operatoren müssen umkehrbar sein, denn dann sind die Mengen der Vorgänger mit der der Nachfolger identisch
- Falls es mehrere Zielknoten gibt, muss diese Suche als Mehrzustandsproblem durchführbar sein. Dies ist möglich, wenn die Zielzustände explizit gegeben sind. Sind nur Zielprädikate gegeben, so wird die Definition von Zuständen schwierig.
- Es muss schnell prüfbar sein, ob ein Knoten schon in einem anderen Teil der Suche vorkommt
- Es muss entscheidbar sein, welche Art der Suche in beiden Richtungen ablaufen soll.
| Optimalität: | ja |
| Vollständigkeit: | ja |
| Zeitaufwand : | O(b^(d/2)) |
| Speicherplatzbedarf: | O(b^(d/2)) |
Was bedeutet "informiert" im Gegensatz zu blinden Suchverfahren?
Bei blinden Suchverfahren kann nicht Einfluss auf die Knotenwahl genommen werden. Informiert bedeutet, dass man dies z.B. mit heuristiken beeinflussen kann.
Heuristische Suchfunktionen
Heuristische Suchalgorithmen versuchen den Suchpfad durch "Schätzen" zu optimieren und somit die Laufzeit zu verbessern. Es wird nun eine Evaluierungsfunktion benötigt, welche die richtige Reihenfolge für die Abarbeitung bestimmt. Die Knoten werden so geordnet, daß der mit der besten Bewertung als Erster expandiert wird. Eine Heuristik ist somit eine spezielle Form einer Evaluations-Funktion.
Best-First-Search
Es wird der Knoten zuerst expandiert, welcher wahrscheinlich am schnellsten zum Ziel führt. Eine von Problem zu Problem verschiedene Evaluations-Funktion hilft hier bei der Entscheidungsfindung. Diese Evaluierungsfunktion kann auch falsch liegen. Wichig ist, dass die Suchzeit im Ganzen sich aber verkürzt. Implementiert wird die Best-First-Suche wie die Breiten- und Tiefensuche auch mittels einer Queue. Nur werden hier vor jeder Expansion die Knoten anhand der Werte der Evaluations-Funktion sortiert. Beispielalgorithmen sind zum BSP Greedy, A*-Search und SMA*...
Arten von heuristischen Suchfunktionen
- Greedy Suche
- A*-Suche
- Speicherbegrenzte Suche
- A*-Suche mit iterativen Vertiefen - IDA*
- Simply Memory-Bounded A* - SMA*
Wie funktioniert die Greedy Suche?
Der Knoten, welcher dem Zielzustandsknoten als am "Naheliegendsten" eingeschätzt wird, wird als Erster expandiert. Eine Funktion, welche solche Kosten schätzt, nennt man Heuristikfunktion. Eine heuristische Funktion h(n) stellt also die Kosten des billigsten Pfades von einem Knoten n zum Zielzustand dar. Jede beliebige Funktion kann als Heuristik verwendet werden.
Es
muss nur gelten h(n) = 0, falls n ein Zielknoten ist.
Die Greedy-Suche arbeitet nach dem Tiefensuchmuster und ist somit
auch nicht optimal und nicht vollständig. Der Worst-Case
Zeitbedarf ist O(bm), mit m als maximale Tiefe des Suchraumes.
| Optimalität: | nein |
| Vollständigkeit: | nein |
| Zeitaufwand : | O(b^m) (worst Case) |
| Speicherplatzbedarf: | O(b*m) |
Wie funktioniert die A*-Suche?
Durch Addition der heuristischen Funktion h und der Pfadkostenfunktion g erhält man die Funktion f(n) = g(n) + h(n). Dabei sind g(n) alle bisherigen Kosten und h(n) die aktuellen Kosten. Die A*-Suche arbeitet im Grunde wie Greedy. Es wird nur g(n) hinzuaddiert.
Hat die Funktion h die Eigenschaft, dass die Kosten eines Pfades bis zu einem Zielknoten nicht überschätzt werden, dann ist es eine zulässige Heuristik. Die Best-First-Suche unter Verwendung von f als Evaluierungsfunktion mit zulässigem h heißt A*-Suche. Eine heuristische Funktion, deren Werte entlang des Pfades niemals kleiner werden, nennt man monoton. Ist eine heuristische Funktion nicht monoton, dann kann sie durch die Pfadmaximierungsgleichung (Maximum bilden) in eine Monotone umgeformt werden.
Die A*-Suche ist optimal und vollständig, aber im Worst-Case
exponentiell, da sie der Breitensuche ähnelt.
| Optimalität: | ja |
| Vollständigkeit: | ja |
| Zeitaufwand : | O(b^m) (worst Case) |
| Speicherplatzbedarf: | O(b*m) |
Die speicherbegrenzte A*-Suche mit iterativen Vertiefen - IDA*
Arbeitet wie Suche mit iterativen Vertiefen, nur dass die Suche nicht strikt tiefenorientiert ist, sondern kostenorieniert.
IDA* ist optimal und vollständig und benötigt nur Speicherplatz, der proportional zum längsten Pfad, der untersucht wird, ist. Somit ist Speicherplatzaufwand linear.
| Optimalität: | ja |
| Vollständigkeit: | ja |
| Zeitaufwand : | O(b^m) (worst Case) |
| Speicherplatzbedarf: | O(b*m) |
Die speicherbegrenzte Simply Memory-Bounded A* - SMA*
Der SMA* merkt sich Knoten, welche er schon mal expandiert hat. Somit wird Sucheffizienz erhöht. SMA* hat folgende Eigenschaften:
- Benutzt allen verfügbaren Speicher
- Vermeidet Zustandswiederholungen, soweit Speicher es erlaubt
- Ist vollständig, wenn Speicher ausreicht, um kürzesten Suchpfad zu speichern
- Ist optimal, wenn Speicher ausreicht, um kürzesten optimalen Lösungspfad zu speichern. Andernfalls liefert er die beste Lösung, die mit dem verfügbaren Speicher möglich ist.
- Er ist optimal effizient, wenn der Speicher für den gesamten Suchbaum
ausreicht.
Soll ein Knoten expandiert werden und es ist kein Speicher mehr frei, so wird ein Knoten aus der Liste entfernt. Solche entfernten Knoten heißen vergessene Knoten. Bevorzugt werden solche Knoten entfernt, welche keine gute Lösung versprechen, d.h. hohe f-Kosten haben. Im Vorgängerknoten eines entfernten Teilbaums werden aber Informationen über die Qualität des besten Pfades in dem entfernten Teilbaum abgelegt, um dadurch einen solchen Teilbaum im Falle des Falles wieder rekonstruieren zu können.
Problemlösen durch Optimieren
Abgrenzung
Der Unterschied zur Suche ist, daß bei Suche der Anfangszustand gegeben ist und die Lösung gesucht wird. Beim Optimieren ist die Lösung schon im Anfangszustand gegeben und es wird versucht eine bessere Lösung zu ermitteln.
- Zielzustände werden über Zielfunktionen bewertet
- Durch das Optimieren wird versucht einen besseren Zielzustand zu finden
- Speichern immer nur einen Zustand
Drei Ansätze beim Optimieren
- Bergsteigen
- Simuliertes Ausglühen
- Genetische Algorithmen
"Bergsteigen" als Optimierung
Das Bergsteigen ist ein stures Suchen von besseren Werten. Gibt es mehrere bessere Knoten, muß via Zufallsfunktion einer selektiert werden.
Welche drei Probleme treten beim "Bergsteigen" auf?
Lokales Maximum
Stößt die Suche auf ein lokales Maximum, bleibt sie dort hängen und findet ein evtuelles globales Maximum nicht.
Plateau
Einmal auf einer Ebene sitzend, kann der Algorithmus nur raten, in welche Richtung fortgesetzt werden soll.
Grat
Man benötigt Operatoren, welche verhindern, daß die Suche entlang eines Grates hin und her pendelt.
Um diese Problemen aus dem Weg zu gehen, kann man die Suche durch Bergsteigen mehrfach von verschiedenen zufällig gewählten Startpunkten aus durchführen und die besten Werte nehmen.
Simuliertes Ausglühen
Die Idee ist, während der Suche in zufälligen Abständen Knoten mit schlechteren Werten auszuwählen, um auf diese Weise lokalen Maxima zu entgehen. Eine Variable T beschreibt im Algorithmus eine Art Temperatur (die die Wahrscheinlichkeit von Abwärtsschritten steuert)
- T wird bei jeder Iteration inkrementiert
- Anfangs ist T relativ hoch und es besteht somit eine hohe Wahrscheinlichkeit des Abwärtsgehens
- Mit richtigen Parametern findet das Ausglühen also das globale Maximum
- Ist vollständig und optimal, wenn ein entsprechend langer Zeitraum für das Ausglühen gegeben ist
Genetische Algorithmen
Dieser Ansatz ist aus der Evolutionstheorie abgeschaut. Man nimmt an das die Evolution immer optimale Pfade wählt und somit optimale Wesen hervorbringt.
Genetische Algorithmen laufen auf Populationen von Genomen (Folge von Genen = Bitstrings) ab. Sie erzeugen in großen Schleife neue Generationen von Genomen durch Anwendung der drei Operatoren Selektion, Kreuzung und Mutation. Dabei werden folgende Schritte durchgeführt:
- Definiere die Genome und eine Fitneßfunktion (Überlebensfunktion davon abhängig) und erzeuge eine initiale Population von Genomen
- Modifiziere die aktuelle Population durch Anwendung der drei Operatoren
- Wiederhole den letzten Schritt solange, bis sich die Fitness nicht mehr erhöht
Ziel des Algorithmus ist, die Fitness der Genome zu maximieren. Die Fitnessfunktion (kann beliebig sein) bewertet jedes neu entstandene Genom. Dazu muss Genom in seinen ursprünglichen Phänotyp (Erscheinungsbild eines Genotyps) umgewandelt werden, denn auf ihm operiert die Fitnessfunktion. Nachteile von genetischen Algorithmen sind die schlechte Effizienz und die Notwendigkeit einer anspruchsvollen Fitnessfunktion. Beliebtes Anwendungsgebiet sind die neuronalen Netze, wo es vor allem auf die Fitnessfunktion ankommt.
Die drei Operationen genetischer Algorithmen
Selektion
Ist das Aussondern von bestimmten Genomen zum Konstanthalten der Population.Kreuzung
Führt das Auswählen der fittesten Genome und Verkettung bzw. Kombination dieser dar.Mutation
Verändert ein oder mehrere zufällig gewählte Gene eines Genoms, wodurch ein neues Genom entsteht, um vor allem eventuellen lokalen Maxima entgehen zu können.
Kapitel 3 - Agenten, die logisch Schlußfolgern
Wodurch ist ein Wissensbasierter Agent definiert?
Wissensbasis
Die erste zentrale Komponente ist die Wissensbasis (repräsentiert Menge von Fakten über die Welt). Die verschiedenen Repräsentationen werden Sätze genannt, welche in einer Wissensrepräsentationssprache formuliert werden. Zwei grundlegende Funktionen sind notwendig:
- TELL (Hinzufügen von Informationen)
- ASK (Abfragen von Informationen)
Inferenzmaschine
Die zweite wichtige Komponente ist die Inferenzmaschine, welche versucht Wissen zu erschließen. Ein Wissensbasierter Agent ist den Zustandsbasierten ähnlich. Wegen der Wissensbasis und den Aktionen TELL und ASK kann er aber auf drei Ebenen besser beschrieben werden:
- Wissensebene oder epistemologische Ebene (das was der Agent weiß)
- Logische Ebene (Kodierung des Wissens in Sätzen)
- Implementationsebene (physikalische Repräsentation der Sätze auf irgendeiner gewählten Agentenarchitektur)
Das initiale Programm kann durch Einfügen von Sätzen aufgebaut werden (deklarativer Ansatz).
Was ist ein autonomer Agent?
Hat der Agent einen Lernmechanismus, dann wird er als autonom bezeichnet.
Wissensrepräsentation und Wissensrepräsentationssprache
Ziel der Wissensrepräsentation ist es, Wissen in einer für den Rechner verständlichen Form zu kodieren. Eine Wissensrepräsentationssprache definiert sich durch:
- Syntax, beschreibt die korrekte Abbildung von Sätzen
- Semantik, bestimmt die Fakten der Welt, auf die sich die Sätze beziehen
Logischer Konsequenz und Folgerung
Die Unterscheidung von Fakten und Repräsentationen ist von entscheidender Bedeutung. Da die Welt nicht in einen Agenten gebracht werden kann, muß der Agent auf den Repräsentationen schlußfolgern und kann nicht direkt auf den Fakten arbeiten.
Schlußfolgern ist also ein Prozeß, welcher neue Konfigurationen aus bestehenden ableitet.
Logische Konsequenz bzw. logische Folgerung heißt, daß man nur solche Sätze erzeugen möchte, die zwingend war sind, wenn die Ausgangssätze wahr sind. Man sagt "aus KB folgt logisch a" (Knowledge Base und gefolgerter Satz a).
Worin unterscheiden sich Korrektheit und Vollständigkeit einer Inferenzprozedur?
- Eine Inferenzprozedur die nur logische folgende Sätze erzeugt, heißt korrekt.
- Eine Inferenzprozedur die alle logisch folgenden Sätze ableiten kann, heißt vollständig.
Unterschiede der Repräsentationen von Programmiersprachen und natürliche Sprachen
Programmiersprachen
- Besonders gut geeignet, um Algorithmen und Datenstrukturen zu formulieren
- Ungeeignet, um unpräzise formulierte Sachverhalte zu beschreiben
- Die Unbestimmtheit einer Aussage ist schwer formulierbar
- BSP: in (2,2) oder (2,1) ist eine Fallgrube
Natürliche Sprachen
- Sind ausdrucksstark und lassen beliebige Inhalte zu
- Wurden aber nicht für Wissensrepräsentation entworfen sondern zur menschlichen Kommunikation
- Bedeutung einer Aussage ist hier meist nur aus dem Kontext heraus sichtbar und oft auch nicht eindeutig.
- Natürliche Sprachen sind also extrem Kontext- und Situationsbezogen
Kombination beider Sprachen
- Wissensrepräsentationssprache muß die Vorteile beider Sprachen kombinieren
- Wissensrepräsentationssprachen stellen eine semantische Beziehung zwischen den Sätzen und den Fakten her
- Sie sind normalerweise kompositionale Sprachen, d.h. das die Bedeutung solcher Sätze eine Funktion der Bedeutung seiner Teile darstellt.
Kompositionalität
Kompositionalität ist die Beziehung zwischen Semantik und Syntax verschiedener aufeinander folgender Sätze.
Inferenzen
Inferenzen sind Schlußfolgerungsverfahren. Korrekte Inferenzen werden Deduktion genannt. Eine Logik heißt gültig oder notwendig wahr, wenn er unter allen möglichen Interpretationen in allen möglichen Welten war ist.
- Bsp.: "Dame X ist bedroht oder Dame X ist nicht bedroht."
- Ist in der Welt Damen auf Schachbrett immer wahr, egal welche Situation vorliegt.
Ein Satz der Logik heißt erfüllbar genau dann, wenn es eine Interpretation in einer Welt gibt, unter der der Satz war ist. Ansonsten ist der Satz unerfüllbar.
Eine formale Inferenz mit einer korrekten Inferenzprozedur garantiert, daß nur korrekte Sätze abgeleitet werden.
Deduktion
Detuktion beschreibt korrekte Inferenzen.
Was sind die zwei grundlegenden Bestandteile einer Logik?
Formale Sprache zur Beschreibung eines Sachverhalts
- Syntax
- Semantik
Beweistheorie
- Eine Menge von Regeln zum Ableiten der logischen Folgerungen
Was unterscheidet die Aussagenlogik von der Logik erster Ordnung?
In der Aussagenlogik werden ganze Aussagen oder Fakten durch einzelne Symbole repräsentiert. Solche Symbole können durch boolesche Operatoren verknüpft werden. Die Aussagenlogik ist kaum zur Repräsentation von Objekten geeignet und deshalb als Repräsentationssprache ungeeignet. Die Logik erster Ordnung trägt wesentlich mehr zur Repräsentation der Welt bei:
- Sie kann Objekte und Prädikate über Objekte stellen
- Sie erlaubt mittels Junktoren und Quantoren Sätze über alles in dieser Welt zu formulieren
Bestandteile der Syntax der Aussagenlogik
Symbolvorrat der Aussagenlogik:
- Konstanten (True,False)
- Aussagensymbole (P,Q...)
- Junktoren (&,|,!...)
- Klammern (,)
Dabei gilt
- Jede Konstante und jedes Symbol sind Sätze
- Ist a ein Satz, dann ist (a) auch ein Satz
- Aus einem oder mehreren Sätzen können mit Junktoren neue gebildet werden, durch Konjunktion zweier Konjunkte oder Disjunktion zweiter Disjunkte, Implikation von Prämisse zur Konklusion, Äquivalenz, Negation
Ein Literal ist ein atomarer oder negiert atomarer Satz
Die Bedeutung zusammengesetzter Sätze läßt sich über Wahrheitstabellen ermitteln. Es werden Präzedenzregeln angewendet, um Klammerungen zu sparen. Zu beachten ist die Implikation, welche keine kausalen Gegebenheiten beschreiben kann.
Wahrheitstabellen
Mit Wahrheitstabellen läßt sich die Gültigkeit testen. Sie Stellen ein Beweisverfahren dar, was unabhängig von der Bedeutung der Teilaussagen ist.
Das Modell
Jede Welt, in der ein Satz unter einer bestimmten Interpretation wahr ist, ist ein Modell des Satzes unter dieser Interpretation.
Inferenzregeln
Beweise für Gültigkeit mit Wahrheitstabellen zeigen, dass sich immer bestimmte Muster wiederholen. Jedes dieser Muster beschreibt eine Inferenzklasse und kann durch Inferenzregeln beschrieben werden. Eine Inferenzregel muß einmal bewiesen werden und kann dann beliebig oft angewendet werden. Inferenzregeln werden in der Aussagenlogik durch einen Quotienten zweier Sätze beschrieben. Alle konkreten Sätze die zu den durch die Inferenzregel vorgegebenen Strukturen passen, erfüllen die Inferenzregel.
Folgende Regeln sind gebräuchlich:
- Modus ponens oder Implikationsbeseitigung
- Und-Beseitigung
- Und-Einführung
- Oder-Einführung (Oder-Beseitigung nicht möglich)
- Beseitigung der doppelten Negation
- Unit Resolution (wenn b nicht gilt muß a gelten)
- Resolution (Transitivität nutzen)
Welche Eigenschaften gelten speziell für die aussagenlogische Inferenz?
Das Problem der Erfüllbarkeit aussagenlogischer Sätze ist NP-vollständig.
Monotonizität der Logik heißt, dass alle Sätze aus einer
Wissensbasis, auch aus jeder Obermenge der Wissensbasis folgbar sind.
Horn-Sätze sind Sätze, auf denen Inferenzen in polynomieller Zeit anwendbar sind.
Kapitel 4 - Logik erster Ordnung
Eigenschaften der Logik erster Ordnung
Nach der Logik erster Ordnung besteht die Welt aus Objekten, d.h. Dingen, die individuelle Identitäten und Eigenschaften haben, welche die Objekte differenzieren. Zwischen Objekten können Relationen bestehen. Einige der Relationen können Funktionen sein.
Satzaufbau in der Logik erster Ordnung
Es gibt wie in der Aussagenlogik Sätze, welche die Welt repräsentieren.
Sätze bestehen aus Thermen und Prädikatsymbolen. Terme können funktionale Ausdrücke, Variablen oder Konstanten sein. Aus einfachen Sätzen werden durch Junktoren und Quantoren komplexe Sätze gebaut.
Symbolvorrat der Logik erster Ordnung
- Konstantensymbole
- Prädikatsymbole
- Funktionssymbole
- Terme
- Atomare Sätze
- Zusammengesetzte Sätze
- Quantoren
- Universelle Quantifizierung mit dem Allquantor
- Existentielle Quantifizierung
- Geschachtelte Quantoren
- Quantoren und Negation
- Gleichheit
Merkmale von Konstantensymbolen
Durch Interpretation wird festgelegt, auf welches Objekt in der Welt sich ein Konstantensymbol bezieht. Jedes Konstantensymbol benennt genau ein Objekt. Aber nicht alle Objekte der Welt müssen aber Namen haben und Mehrfachbenennungen sind zugelassen.
Prädikatsymbole
Durch Interpretation wird festgelegt, auf welche Relation in der Welt sich ein Prädikatsymbol bezieht. Eine Relation ist eine Menge von Tupeln von Objekten, die die Relation erfüllen.
Funktionssymbole
Funktionssymboel werden durch Interpretation auf spezielle Relationen abgebildet, die in einer bestimmten Stelle (üblicherweise die Letzte) eindeutig sind. Eine n-stellige Funktion kann durch eine Menge von (n+1) Tupeln definiert werden. Die letzte Stelle eines solchen Tupels stellt den Wert der Funktion unter den ersten n Stellen dar.
Terme
Ein Term ist ein logischer Ausdruck der sich auf ein Objekt in der Modellwelt bezieht. Somit sind auch Konstanten- und Variablensymbole Terme. Außer Konstantensymbolen sind Ausdrücke, gebildet aus einem Funktionssymbol und einer in Klammern eingeschlossenen Folge von Termen, wieder Terme. Ein Term der keine Variablen enthält, heißt Grundterm.
Atomare Sätze (Atome)
Atomare Sätze bestehen aus einem Prädikatsymbol gefolgt von einer in Klammern eingeschlossenen Liste von Termen. Ein atomarer Satz beschreibt einen Fakt, dessen Bedeutung entweder true oder false ist. Ein atomarer Satz ist wahr, wenn die Relation, auf die sich das Prädikatsymbol bezieht, zwischen den Objekten gilt, auf denen sich die Terme beziehen.
Zusammengesetzte Sätze
Mittels Junktoren können aus Sätzen komplexere Sätze gebildet werden. Die Teilsätze können zusammengesetzt oder auch atomar sein. Die Semantik zusammengesetzter Sätze sind Wahrheitswerte und sind analog zur Aussagenlogik definiert.
Quantorenarten
Universelle Quantifizierung über den Allquantor
- Katzen sind Säugetiere
- = Alle Katzen sind Säugetiere
- V x Katze(x) => Säugetier(x)
Existentielle Quantifizierung
- Zur Repräsentation natürlich sprachlicher Sätze, die Aussagen über einige Objekte aus einer Menge machen
- Micky hat eine Schwester, die eine Katze ist
Es gibt x Schwester (x, Micky) & Katze (x); die Auflösung wird disjunktiv verknüpft
Geschachtelte Quantoren
- Gleichartige Quantoren werden abkürzend zusammengefaßt
- Kommen Allquatoren und Existenzquatoren gemischt vor, dann ist Reihenfolge wichtig
Quantoren und Negation
- Anwendung der De Morganschen Regeln
Welche Merkmale definieren die Gleichheit?
Das Gleichheitszeichen kann als eine Art spezielles Prädikat verwendet werden. Sind t1 und t2 Terme, dann ist t1 = t2 ein Satz.Zwei Anwendungsbereiche der Logik erster Ordnung
Die Verwandtschaftsdomäne
In der Verwandtschaftsdomäne gibt es- Objekte: Personen
- Einstellige Prädikate: Männlich, Weiblich
- Zweistellige Prädikate: Elternteil, Geschwister, Bruder, Kind, Enkel
- Funktionen: Mutter,Vater
Mittels Definitionen kann man aus diesen Axiomen neue Konzepte erzeugen und neue Axiome ableiten. Beim Aufbau einer Wissensbasis gibt es zwei Probleme
- Reichen die Axiome und Definitionen zur Beschreibung einer Domäne aus?
- Ist die Domände durch die Axiome und Definitionen überspezifiziert?
Die Mengendomäne
In der Mengendomäne gibt es- Konstanten: LeereMenge
- Prädikate: Element,Teilmenge,Menge
- Funktionen: Durchschnitt, Vereinigung, Einfügen
- Axiome und Fakten einer Domäne werden mittels Tell in die Knowledge Base eingefügt. (Zusicherungen)
- Mittels Ask können dann logische Konsequenzen aus den Sätzen abgefragt werden. (Fragen oder Ziele)
Repräsentation von Veränderungen in der Welt
Diachronische Regeln
Diachronische Regeln, sind Regeln, welche beschreiben, wie sich eine Welt verändert oder auch nicht verändert.
Was beschreibt ein Situationskalkül?
Die Welt wird als eine Folge von Situationen betrachtet. Jede Situation stellt
einen "Schnappschuß" des Zustandes der Welt zu dem Augenblick dar. Eine Situation
wird aus einer anderen durch Aktionen erstellt kann benannt werden.
Um den Wechsel einer Situation zur nächsten zu beschreiben, wird eine Funktion
benutzt:
- Ergebnis(Aktion, Situation)
- Ihr Wert ist eine neue Situation
- Die Situation entsteht, wenn die Aktion auf die Situation angewendet wird
Aktionen, welche eine Wirkung auf die Folgesituation haben sind
Wirkungsaxiome.
Axiome, welche Sicherstellen, dass eine Wirkung über mehrere Situationen erhalten
bleibt, sind Frameaxiome. Wirkungsaxiome und Frameaxiome zusammen,
beschreiben vollständig, wie sich eine Welt aufgrund der Aktionen des Agenten
entwickelt.
Wofür benötigt ein Agent eine Ortsbestimmung?
"Am Beispiel der Wumpus Welt ist die Ortsbestimmung besonders wichtig " Der Agent muss wissen, in welche Richtung er blickt o Hier einfach durch einen Winkel definiert" Der Agent benötigt eine einfache Landkarte, um aus einer Richtung und einer Ortsangabe eine neue Ortsangabe berechnen zu können.
Ableiten verborgener Eigenschaften einer Welt
Kausale und Diagnostische Regeln
Synchrone Regeln setzen verschiedene Eigenschaften desselben Weltzustandes in Relation.
Kausale Regeln
Geben die Richtung einer angenommenen Kausalität in einer Welt wieder. Systeme, die mit kausalen Regeln schlußfolgern, heißen modellbasierte Schlußfolgerungssysteme.
Diagnostische Regeln
Leiten das Vorhandensein verborgener Eigenschaften direkt aus den Wahrnehmungen ab. Man kann aber keine so aussagekräftigen Schlüsse ziehen, wie das bei Kausalen Regeln der Fall ist.
Präferenzen zwischen Aktionen bei Zielbasierte Agenten
Die Wünschbarkeit von Aktionen wird durch bestimmt Prädikate
beschrieben. Prädikate können sein Gut, Mittel, Riskant oder Tödlich.
Die Auswahl einer Aktion erfolgt gemäß der Reihenfolge, welche die Prädikate auf
Grund ihrer Semantik haben. Regeln dieser Art heißen
Aktions-Wert-Regeln.
Mit welchen drei Methoden lassen sich Aktionsfolgen bestimmen?
Inferenz
Mit geeigneten Axiomen kann man mit ASK eine Aktionsfolge aus der Wissensbasis ableiten. Für größere Welten wäre aber der Rechenaufwand zu groß.
Suchen
Mit Best-First-Suche kann ein Pfad zum Ziel bestimmt werden. Dazu muss Wissen in eine Menge geeigneter Operatoren und Zustandsrepräsentationen umgeformt werden.
Planen
Erfolgt mit speziellen Schlußfolgerungssystemen, die entworfen wurden, über Aktionen zu folgern.
Inferenzen in der Logik erster Ordnung
Welche drei zusätzlichen Inferenzregeln gibt es?
- Allquator - Beseitigung (für alle...)
- Existenzquantor - Beseitigung (Es gibt...)
- Existenzquantor - Einführung
Der verallgemeinerte Modus Ponens und Unifikation
Der Modus ponems enthält die n+1 Prämissen und die Konklusion der
Substitution. Vor Anwendung werden alle Sätze in die kanonische Form (Hornsätze)
umgewandelt.
Sind entweder atomare Sätze oder Implikationen mit einer Konjunktion atomarer Sätze
auf der linken und einem einzelnen atomaren Satz auf der anderen Seite. Einfügen in
die Wissensbasis werden alle Sätze in Hornsätze umgewandelt durch Anwendung der
Inferenzregeln:
- Existenzquantor-Beseitigung
- Und-Beseitigung
- Weglassen der Allquatoren
Unifikation
Es wird angenommen, dass es eine Prozedur UNIFY gibt, die zwei atomare Sätze p und q zu einer Substitution überführt, die die beiden Eingabesätze identisch macht. Konflikte durch doppelte Variablennamen werden durch Umbenennung aufgelöst. Falls ein Unifikator für q und p exisitert, soll UNIFY immer den allgemeinsten Unfikator liefern.
Vorwärts- und Rückwärtsverkettung und wozu braucht man sie?
Es gibt einen Satz und man möchte diese über die Wissensbasis vergleichen.
Vorwärtsverkettung
- Üblicherweise durch hinzufügen eines meist atomaren Satzes zur KB
- Als Teil der Tell-Funktion realisierbar
- Es werden alle Implikationen betrachtet
- Gelten auch die übrigen Teile der Antezedenzien dieser Implikation kann das Sukzedenz der Implikation zur Wissensbasis zugefügt werden
Rückwärtsverkettung
Hiermit ist es möglich, alle Antworten auf eine Frage an eine KB zu bekommen. Realisiert wird dies über über die ASK-Funktion. Die Rückwärtsverkettung arbeitet folgendermaßen:
- Prüft zunächst, ob die Antworten auf die Frage direkt von der KB geliefert werden kann
- Dann wird nach allen Implikationen gesucht, deren Sukzedenz mit der Frage unifizierbar sind
- Dann wird versucht, die Antezedenzien dieser Implikation wiederrum durch Rückwärtsverkettung zu beweisen (Konjunkte werden hintereinander bewiesen)
- Im Laufe dieser Schritte werden Substitutionen aufgebaut, die ausgegeben werden
Resolution: Eine vollständige Inferenzprozedur
Die Inferenzregel Resolution
Diese Inferenzregel ist eine Resolution-Regel in erweiterter Form. Es wird erlaubt, dass Disjunktionen mehrere Elemente enthalten. Sie wird auf Sätze der Logik erster Ordnung erweitert:
- Es muß unifiziert werden
- Substitutionen der Ausgangssätze werden abgeleitet
- Die Resolution Regel ist eine Erweiterung des Modus Ponens
- Die implikative Normalform ist eine Erweiterung der Hornform (linke Seite stimmt mit Hornform überein, aber auf rechter Seite ist Disjunktion von Atomen erlaubt)
- Der Modus Ponens ist ein Spezialfall der Resolution-Regel in implikativer Form, welcher aber kein vollständiges Beweissystem wie die verallgemeinerte Resolution Regel ist
Schritte bei der Umformungung in die implikative Normalform
- Beseitigung der Implikationen
- Negationen nach innen ziehen
- Umbenennung von Variablen
- Quantoren nach außen ziehen
- Skolemisierung (Entfernen der Existenzquantoren)
- Distribution von Konjunktion über Disjunktion (Distributivgesetz)
- Abflachen eingebetteter Strukturen (Assoziativgesetz)
- Umwandlung von Disjunktionen in Implikationen
Welche zwei Möglichkeiten gibt es zur Behandlung der Gleichheit?
Eine Möglichkeit ist die Axiomisierung, (Eigenschaften als
Äquivalenzrelation).
Zweite Möglichkeit ist spezielle Inferenzregel Demodulation.
Welche vier Resolution-Strategien gibt es?
Unit-Präferenz
Führe, wenn möglich einen Inferenzschritt mit einer Klausel, die nur aus einem Literal besteht durch.
Set of support
Wähle eine Teilmenge "Set of support" der Sätze aus, und wende die Resolution Regel immer auf einen Satz an aus "Set of support" und einen anderen an und füge das Ergebnis in "Set of support" ein.
Input Resolution und Linear Resolution
Wähle die Sätze zur Problembeschreibung als Eingabe und wende die Resolution Regel immer auf einen Satz aus dieser Menge und einem anderen an. Linear Resolution ist vollständig und ist eine Verallgemeinerung der Input Resolution.
Subsumption
Entfernt alle Sätze, die von einem Satz in der Wissensbasis subsumiert werden, d.h. aus diesem Satz logisch folgen. Dadurch kann Suchraum so klein wie nur möglich gehalten werden.
Kapitel 5 - Planen
Die vier Repräsentationen eines suchorientierten Problemlösers
Repräsentation von Aktionen
Aktionen werden dargestellt durch Programme. Sie erzeugen Beschreibungen der Folgezustände.
Repräsentation von Zuständen
Gegeben ist ein vollständiger Anfangszustand. Da Aktionen vollständige Zustandsbeschreibungen erzeugen sind alle Zustände vollständig. Ein Zustand ist meistens eine einfache Datenstruktur.Repräsentation von Zielen
Die einzige verfügbare Information über Ziel ist das Zielprädikat und heuristische Funktion. Die Informationen werden auf die Zustände angewandt, um deren Wünschbarkeit zu bestimmen.Repräsentation von Plänen
Eine Lösung ist eine Folge von Aktionen. Eine Suche betrachtet nur zusammenhängende ununterbrochene Folgen von Aktionen, die beim Anfangszustand beginnen.Die drei Schlüsselideen, die dem Planen zu Grunde liegen
"Öffne" die Repräsentation der Zustände, Ziele und Aktionen
- durch Verwendung geeigneter Repräsentationsformen, wie z.B. die Logik erster Ordnung
- Zustände und Ziele sind darin Sätze
- Aktionen sind logische Beschreibungen von Vorbedingungen und Wirkungen
- So werden Zustände und Aktionen miteinander verbunden
Der Planer kann stets Aktionen zum Plan hinzufügen
- Nicht nur am Anfang, auch mitten in der Planung
- Somit müssen Planung und Ausführung nicht streng getrennt werden
- Durch Verschieben von nicht notwendigen Aktionen nach "hinten" wird dadurch der Verzweigungsfaktor stark reduziert
Meist herrscht Unabhängigkeit von Teilmengen einer Welt
- Deshalb kann oft ein Ziel aus Konjunktion mehrerer unabhängiger Teilziele formuliert werden
- Divide-and-Conquer dafür prädestiniert
Zustände, Ziele und Aktionen in der STRIPS-Sprache
Zustände
Sind Konjunktionen funktionsfreier Grundliterale, bestehend aus Prädikaten angewandt auf Konstanten. Zustandsbeschreibungen müssen nicht vollständig sein, da in einer unzugänglichen Welt der Zustand so gut wie nie vollständig ist.Ziele
Ziele sind Konjunktionen funktionsfreier Literale (Variablen zugelassen).Aktionen
- Aktionsbeschreibung (Beschreibung dessen was Agent an Umgebung ausgibt, um zu handeln)
- Vorbedingung (Konjunktion vom Atomen, die spezifiziert was vor Ausführung gelten muss)
- Wirkung (Konjunktion von Literalen, die beschreibt, wie sich Situation nach Aktion verändert)
- OP(Action(GeheZu(dorthin), Precond(An(hier) and Pfad(hier, dort), Effect(An(dort) and not an (hier))
- Beim Planen sind nur Aktionen enthalten und KEINE Zustände
Was macht ein Situationsraum-Planer?
Er betrachtet Zustände. Ein Situationsraum-Planer ist ein Algorithmus, der im Raum der Situationen oder Zustände einen Pfad von einem Anfangs- zu einem Zielzustand durch Anwendung von der verfügbaren Operationen bestimmt. Dabei gibt es Vorwärts- und Rückwärtsplaner.
Rückswärtsplaner
- Zustände im Allgemeinen nur partiell bestimmt
- Information reicht aber aus, um auf Vorhängerzustände zu schließen
- Nachteil der Rückwärtsplanung ist die Konjunktion der Literale, von denen jedes ein zu erfüllendes Teilziel darstellt
Planraum
Ein Planraum betrachtet nicht die Zustände, sondern die
Aktionen. Ein Planraum ist eine Menge partieller Pläne mit den
dazugehörigen Operationen, die solche Pläne in ebensolche überführen können.
Bei Erstellung eines Plans für ein Problem beginnt man mit einem einfachen
unvollständigen Plan und modifiziert diesen mit den Operatoren solange, bis er
vollständig ist.
Solche Operatoren sind Hinzufügen eines Schrittes, das Ordnen von Schritten und das Instanziieren von Variablen.
- Verfeinerungsoperatoren, beschränken die Menge der vollständigen Pläne durch Bedingungen (Constraints)
- Alle restlichen Operatoren sind Modifikationsoperatoren
Kausale Kanten
Sie Beschreiben den Zweck von Schritten in einem Plan, d.h. welche Vorbedingungen für einen Situationswechsel gelten müssen. Ein Planungsalgorithmus schützt kausale Kanten, so dass zwischen zwei Aktionen die durch eine kausale Kante verbunden sind, keine Aktion eingeschoben werden kann, welche die Vorbedingung aufheben würde.
Muß eine Aktion eingefügt werden, kann der Planungsalgorithmus sie entweder vor der kausalen Kante (Demotion) oder nach ihr (Promotion) einfügen.
Planen mit partiell instanziierten Operatoren
Wie kann man mögliche Bedrohungen kausaler Kanten entdecken und behandeln?
Eine Vorbedingung c stellt eine mögliche Bedrohung einer Vorbedingung c' dar, wenn es einen Unifikator gibt, so dass
UNIFY( c ) = ! UNIFY( c' )
ist. Es gibt drei Wege mögliche Bedrohungen zu behandeln:
Auflösung sofort mit einem Gleichheitsconstraint
Alle möglichen Bedrohungen werden sofort aufgelöst. Dabei wird eine Variable mit einem Wert so vorbelegt, dass ein Widerspruch zu einer anderen Vorbedingung nicht entstehen kann (Gleichheitsconstraint).
Auflösung sofort mit einem Ungleichheitsconstraint
Wie oben, nur dass eine bestimmte Belegung von Variablen ausgeschlossen wird, aber alle anderen erlaubt werden. Ist nur schwer zu implementieren.
Auflösung später
Alle Bedrohungen werden solange ignoriert, bis sie notwendige Bedrohungen werden, d.h. ein expliziter Widerspruch vorliegt. Dann wird durch Demotion oder Promotion aufgelöst. Vorteil ist, dass schwache Festlegungen getroffen werden können. Nachteil ist, dass es schwer zu entscheiden ist, ob ein Plan auch eine Lösung darstellt.
Kapitel 6 - Planen und Handeln und Unsicherheit
Die zwei Wege zur Behandlung eines Problems mit unvollständigen oder inkorrekten Informationen?
Bedingtes Planen
- Es wird ein bedingter Plan konstruiert
- Berücksichtigt jede mögliche Situation
- Agent stellt im Plan durch Sensoraktionen fest, welchen Teil des Plans er verfolgen soll
- Durch die Sensoraktionen werden die Constraints im Plan geprüft
Ausführungsüberwachung
- Agent beobachtet während Ausführung was geschieht
- Dadurch kann er feststellen, wenn etwas anders läuft als geplant
- Der Agent kann dann durch Nachplanen versuchen, sein Ziel trotzdem zu erreichen
Bedingtes Planen
Bedingtes Planen ist das Wesen bedingter Pläne. Zur Formulierung bedingter Pläne benötigt man bedingte Ausdrücke in der Form
"If (Condition,Then,Else)"
Der Agent muß während Ausführung die Bedingungen auf Wahrheit prüfen können.
Dem Agenten werden Fakten durch Wahrnehmungen bekannt, die er sich durch Sensoraktionen besorgen muß. Zusätzlich zum gewöhnlichen Planungsprozeß wird das Konzept des Kontextes eines Schritts im Plan benötigt.
- Ist die Menge aller Bedingungen die gelten müssen, damit der Schritt ausgeführt werden kann
- Er beschreibt im Wesentlichen den Zweig, in dem der Schritt liegt
- Ist ein Kontext eines Schrittest festgelegt, so erben alle Nachfolgschritte diesen.
- Zwei Schritte die in verschiedenen Kontexten liegen können nicht beide ausgeführt werden
- Deshalb können sich solche Schritte nicht beeinflussen
- Kontexte wichtig, um Buch zu führen, welche Schritte die Vorbedingungen welcher Anderen verletzen oder bestätigen würden
Laufzeitvariable sind Variablen, welche erst während der Ausführung mit Werten belegt werden.
Zusammenhang zwischen Planung und Ausführung
Es herrscht vollständige Integration von Planung und Ausführung. Planung und
Ausführung werden im folgenden nicht mehr als getrennte Prozesse betrachtet.
Vielmehr werden sie zu einem situierten Planungsagenten zusammengefaßt. Dieser
Agent wird selbst als Teil eines großen Plans betrachtet - seines
Lebensplans.
Seine Aktivitäten sind:
- Ausführen einiger Schritte des Plans, die zur Ausführung anstehen
- Verfeinern des Plans um eventuelle Mängel zu eliminieren
- Verfeinern des Plans aufgrund zusätzlich gewonnener Informationen
- Überarbeiten des Plans, aufgrund unerwarteter Veränderungen der Umwelt
Der Agent kann bereits mit der Planausführung beginnen, wenn der Plan noch nicht komplett berechnet wurde. Insbesondere wenn der Plan unabhängige Teilziele erhält, lässt sich so viel Zeit sparen.
Unsicherheit
Handeln unter Unsicherheit
Agenten haben in Realität fast nie Zugang zur vollständigen Wahrheit über ihre
Umgebung. Es gibt fast immer fragen, welche kategorisch beantwortet werden können.
Deshalb muß der Agent in der Lage sein, unter Unsicherheit zu handeln.
Unsicherheit kann auch dadurch entstehen, wenn der Agent seine Umwelt falsch
interpretiert oder nur unvollständig wahrnimmt.
Qualifikationsprobleme
Viele Regeln über den Anwendungsbereich können auf Grund der zu großen
Komplexität, oder einfach weil einige unbekannt sind, unvollständig sein.
Die Wahl der richtigen Aktion, d.h. die rationale Entscheidung ist abhängig von der
Relativen Wichtigkeit verschiedener Ziele und der Wahrscheinlichkeit, daß sie und
bis zu welchem Grad sie erreicht werden.
Weshalb ist die Behandlung von unsicheren Wissen notwendig?
Behandlung von unsicherem Wissen in einem Bereich, welcher einen sehr hohen Anteil an unsicheren Wissen bereitstellt, scheitert aus drei Gründen (Bsp.: Medizin)
- Faulheit, da es viel zu Aufwendig ist, die vollständige Menge an Voraussetzungen und Konsequenzen einzugeben
- Theoretische Unwissenheit, da das Gebiet selbst keine vollständige Theorie besitzt
- Praktische Unwissenheit, da selbst wenn alle Regeln bekannt wären, das Risiko viel zu hoch wäre (Bsp. Patienten)
Über welchen Ansatz wird mit unsicherem Wissen umgegangen?
- Es wird mit Wahrscheinlichkeiten gearbeitet
- Die Verknüpfung von Ursachen und Diagnose ist keine logische Konsequenz
- Deshalb können auch keine Wahr / Falsch Aussagen getroffen werden, sondern bestenfalls ein Grad an Überzeugung
- Umgesetzt wird dies durch einen Wahrscheinlichkeitswert zwischen null (Wahrscheinlich falsch) und eins (wahrscheinlich wahr)
- Sätze welche subjektiv sind oder durch Vereinbarung festgelegt wurden, werden mit der Fuzzy-Logik behandelt
Evidenz
- Die Wahrscheinlichkeit, die ein Agent einem Satz zuordnet, hängt von den Wahrnehmungen ab, die er bis zum aktuellen Zeitpunkt ermittelt hat. Dieser Sachverhalt ist die Evidenz.
- Somit können sich die Wahrscheinlichkeiten einer Wissensbasis ändern, wenn mehr Evidenz gewonnen wurde.
- Deshalb müssen alle Wahrscheinlichkeitsaussagen einen Hinweis ihre Evidenz enthalten
- Wahrscheinlichkeiten die vor Erhalt einer Evidenz gemacht werden, heißen a priori oder unbedingte Wahrscheinlichkeiten, die restlichen postpriori- oder bedingte Wahrscheinlichkeiten
A Priori Wahrscheinlichkeit
- Ist die unbedingte Wahrscheinlichkeit P(A)
- Diese Aussage kann nur getroffen werden, wenn keine andere Information in diesem Kontext vorliegt
- Liegt eine neue Information vor, kann nur noch eine bedingte Wahrscheinlichkeit getroffen werden
Was heißt A Postpriori Wahrscheinlichkeit?
- Ist die bedingte Wahrscheinlichkeit P(A | B)
- Sobald der Agent Evidenz über eine bisher unbekannte Aussage erhält, kann er keine unbedingte Wahrscheinlichkeit mehr zuordnen
- Er kann nun bedingte Werte zuordnen: "die Wahrscheinlichkeit von A unter der Voraussetzung, daß B alles ist, was bekannt ist"
- Bei der Formulierung von P(A | B) ist darauf zu achten, daß keine weiter Information C vorliegt.
- Ist dies der Fall, so kann man nur die a postpriori Wahrscheinlichkeit P( A | B and C ) angegeben werden
Die drei Wahrscheinlichkeitsaxiome
- Alle Wahrscheinlichkeiten liegen zwischen 0 und 1
- Notwendigerweise wahre Aussagen haben Wahrscheinlichkeit 1, notwendigerweise Falsche die Wahrscheinlichkeit 0
- Die Wahrscheinlichkeit einer Disjunktion ist definiert durch P(A oder B) = P(A) + P(B) - P(A und B)
Kombinierte Wahrscheinlichkeitsverteilung
- Ein probabilistisches Modell einer Domäne besteht aus einer Menge von Zufallsvariablen, die einzelne Werte mit bestimmten Wahrscheinlichkeiten annehmen können
- Ein atomares Ereignis ist eine Zuordnung einzelner Werte zu allen Variablen
- Die kombinierte Wahrscheinlichkeitsverteilung P(X1...Xn) ordnet allen möglichen atomaren Ereignissen Wahrscheinlichkeiten zu
- Da sich atomare Ereignisse gegenseitig ausschließen, ist ihre Konjunktion zwangsweise falsch und ihre Disjunkion zwangsweise wahr.
Die Bayessche Regel
- Durch gleichsetzen der Produktregeln erhält man die Gleichung für die Bayessche Regel
- Alle probabilistischen Systeme in der KI basieren auf ihr
- Die Gleichung repräsentiert wieder eine Menge von Gleichungen, die die entsprechenden Elemente in der Ergebnistabelle zueinander in Beziehung setzen
Kapitel 7 - Lernen aus Beobachten
Die Bestandteile des Allgemeinen Modells lernender Agenten
- Performanzelement
- Lernelement
- Kritik
- Problemgenerator
Das Performanzelement
Es wählt externe Aktionen auf Grund von Wahrnehmungen aus. Es steht also für das, was bisher der ganze Agent war.
Dsa Lernelement
Das Lernelement ist dafür zuständig Verbesserungen vorzunehmen. Es nimmt als Input Wissen über das Performanzelement und die Rückmeldung aus der Kritikeinheit. Es gibt Verbesserungen an das Performanzelement aus, so daß sich der Agent in Folgeaktionen besser verhält.
Die Kritik-Einheit
Sie beurteilt das Verhalten des Agenten und sagt dem Lernelement, wie gut sich der Agent verhält. Sie verwendet als Referenz einen fixen extern eingegebenen Performanzstandart, welcher nicht Teil des Agenten ist. Diese Referenz ist notwendig, weil die Wahrnehmungen des Agenten alleine nicht ausreichen, um Aussagen über die Qualität des Agenten treffen zu können. Wäre der Performanzstandard Bestandteil des Agenten, könnte er den Standard an sein Verhalten anpassen.
Was soll der Problemgenerator bewirken?
Er Schlägt Aktionen vor, die zu neuen und informativen Erfahrungen führen. Diese Einheit verleit dem Agenten ein exploratives Verhalten. Ohne diese Einheit, würde der Agent nie etwas neues probieren, sondern immer nur Aktionen basierend auf seinem aktuellen Wissen ausführen.
An welchen vier Punkten orientiert sich der Entwurf des Lernelements?
- Welche Komponenten des Performanzelements müssen verbessert werden?
- Welche Repräsentation wird für diese Komponenten benutzt?
- Welche Rückmeldung ist erhältlich?
- Welche Vorabinformation ist erhältlich?
Weitere Komponenten eines Performanzelements
- Direkte Abbildung von Bedingungen auf Aktionen über den aktuellen Zustand
- Hilfsmittel zur Ableitung relevanter Eigenschaften der Welt aus den Wahrnehmungsfolgen
- Informationen über Art und Weise, wie sich Welt verändert
- Informationen über Ergebnisse möglicher Aktionen des Agenten
- Nützlichkeitsinformationen, die die Wünschbarkeit von Weltzuständen anzeigen
- Action-Wert-Informationen, welche die Wünschbarkeit spezieller Aktionen in speziellen Weltzuständen anzeigen
- Ziele, die Klassen von Zuständen definieren, deren Erreichen den Nutzen des Agenten Maximieren
Jede dieser Komponenten kann gelernt werden, wenn der Agent das entsprechende Feedback erhält. Die Komponenten können unterschiedlich repräsentiert werden (logische Sätze oder probabilistische Formalismen wie Bayessche Netze). Es gibt verschiedenste Lernalgorithmen, welche aber alle auf der gleichen Grundlage operieren.
Drei grundlegende Methoden des Lernens
Überwachendes Lernen
Der Agent kann das Ergebnis seiner Aktionen beobachten oder es wird ihm mitgeteilt. ("Lernen durch Lehrer")
Reinforcement Learning
Der Agent erhält eine Reaktion als Belohnung oder Bestrafung. Es wird ihm aber nicht gesagt, was die richtige Aktion ist. Das muß Agent selbst erforschen.
Nicht überwachendes Lernen
Der Agent erhält kein Feedback über die Wirkungen seiner Aktionen. Er kann nur Beziehungen zwischen seinen Wahrnehmungen lernen. Falls er keine Nutzenfunktion hat, kann der Agent nicht lernen was er tun soll.
Induktives Lernen
Beim überwachenden Lernen bekommt der Lehrer eine Menge von Beispielen vorgelegt und soll daraus eine Funktion erlernen. Beispiele haben die Form (x,f(x)), mit x als Eingabe und f(x) als Ausgabe der zu lernenden Funktion.
Eine reine induktive Inferenz (Induktion) besteht aus der Aufgabe:
- Bestimme auf Basis einer Menge von Beispielen von f eine Funktion h, genannt die Hypothese, welche f approximiert
- Im Allgemeinen können viele Hypothesen aus Beispielen generiert werden
- Wird einer Hypothese einer anderen bevorzugt, so heißt dies ein Bias
- Da es meist immer eine Großzahl konsistenter Hypothesen gibt, haben Lernalgorithmen einen irgendwie gearteten Bias
Die einfachste Form eines lernenden Agenten ist ein reflexiver lernender Agent. Er kann (Wahrnehmung, Aktion)-Paare erlernen. Die Grundstruktur eines solchen Agenten besteht aus
- REFLEX-PERFORMANCE-ELEMENT
- REFLEX-LEARNING-ELEMENT
Die drei Arten von Lernalgorithmen
- Lernalgorithmen auf Basis Logischer Sätze als Entscheidungsbäume oder Versionsraum-Ansatz
- Lernalgorithmen auf Basis nicht linearer numerischer Funktionen als neuronale Netze
- Lernalgorithmen auf Basis Bayesscher Netze
Lernen von Entscheidungsbäumen
Was wissen Sie über Entscheidungsbäume als Performanzelemente?
Ein Entscheidungsbaum nimmt als Eingabe ein Beschreibung eines Objekt oder einer Situation. Er gibt als Ausgabe ein Wahr oder Falsch an und repräsentiert somit eine boolesche Funktion. Eine Repräsentation höherwertiger Funktionen aber auch möglich. Ein innerer Knoten entspricht einen Test auf den Wert einer der Eigenschaften. Ein Blattknoten entspricht einem booleschen Wert.
Welche Ausdruckskraft haben Entscheidungsbäume?
Entscheidungsbäume repräsentieren Mengen von Implikationen. Sie können nicht beliebige Mengen von Sätzen der Logik erster Stufe repräsentieren. Sie können nur Aussagen über einzelne Objekte (Knoten) treffen. Aussagen über eine Objektmenge sind nicht möglich.
Deshalb ist die Entscheidungsbaumsprache im wesentlichen auch aussagenlogisch. Die Ausdruckskraft von Entscheidungsbäumen entspricht genau der der Aussagenlogik.
Jede boolesche Funktion oder aussagenlogischer Satz kann als Baum dargestellt werden. Man braucht nur die Wahrheitstabelle zu iterieren und jede Zeile als Pfad im Baum interpretieren. Nachteilig ist die hohe Komplexität bei bestimmten Eingaben, welche schnell eine exponentielle Größe erreicht.
Was heißt Induktion von Entscheidungsbäumen aus Beispielen und wie geht dies von statten?
Es wird versucht aus einer Menge von Datensätzen einen Baum zu generieren. Ein Beispiel wird durch die Belegung der Attribute und des Zielprädikates spezifiziert. Der Wert des Zielprädikates heißt Klassifikation des Beispiels. Ist ein Wert des Beispiels wahr so ist es eine positive, sonst eine negative Klassifikation. Die gesamte Menge der Beispiele heißt Trainingsmenge.
Bei der Erstellung eines Entscheidungsbaums soll ein Muster extrahiert werden, welches möglichst viele Fälle in knapper Form darstellen kann.
Ein Allgemeines Prinzip induktiven Lernens ist Ockhams Rasiermesser.
"Die wahrscheinlichste Hypothese ist die einfachste, die mit allen Beobachtungen konsistent ist."
Den kleinstmöglichen Entscheidungsbaum zu finden ist nicht lösbar. Aber mit DECITION-TREE-LEARNING ist es möglich, einen kleinen Baum zu finden. Dieser Algorithmus testet immer das wichtigste Attribut zuerst. Damit ist das Attribut gemeint, nach dem sich die Beispiele am meisten unterscheiden.
Verwendung der Informationstheorie
Das Prinzip des Informationsgewinns
Die Implementierung der CHOOSE-ATTRIBUTE Funktion ist grundlegend wichtig. Man benötigt eine Einteilung in gute und unnütze Attribute. Beste Werte sollten perfekten Attributen zugeschrieben werden und kleinste den wertlosen Attributen.
Information
- Ist im Sinne der Shannonschen Informationstheorie zu verstehen
- In diesem Sinn ist eine Information eine Antwort auf eine Frage
- Informativ ist eine Antwort dann, wenn sie neue Erkenntnisse bringt
Der Gehalt einer Information wird in Bits gemessen. Ein Bit genügt, um eine Ja/Nein-Frage zu beantworten. Beim Entscheidungsbaum-Lernen wird die Wichtigkeit der einzelnen Attribute in Abhängigkeit von der Anzahl enthaltener positiver und negativer Beispiele berechnet.
Der Informationsgewinn aus dem Attributtest ist definiert durch die Differenz zwischen dem ursprünglichen Informationsbedarf und dem neuen (Gain(a)).
Die in der CHOOSE-ATTRIBUT genutzte Heuristik ist genau die, die das Attribut mit dem größten Informationsgewinn selektiert.
Rauschen und Overfitting
Ist ein allgemeines Problem und tritt nicht nur beim Entscheidungsbaum-Lernen auf. Wenn eine große Menge möglicher Hypothesen gegeben ist, besteht die Gefahr, daß man bedeutungslose Regelmäßigkeiten in den Daten entdeckt, welche die Laufzeit stark verschlechtern. Overfitting kann durch Pruning vermieden werden.
Pruning
Entdeckte Attribute, welche für Informationsgehalt irrelevant sind werden ignoriert. Dazu müssen aber irrelevante Attribute von relevanten unterschieden werden können. Angenommen man teilt eine Menge von Beispielen mit einem irrelevanten Attribut auf...
Die entstehenden Teilmengen haben dann in der Regel etwa die selbe Verteilung von positiven und negativen Beispielen wie die ursprüngliche Menge. Damit ist der Informationsgewinn annähernd null.
Damit stellt sich aber die Frage, ab wann es sich lohnt ein Attribut zur Aufteilung einer Menge zu verwenden und wann nicht.
Dazu werden Signifikanztests herangezogen...
- Er beginnt mit Annahme, es gebe kein zugrundeliegendes Muster (Nullhypothese)
- Dann wird berechnet, wie weit die Daten vom vollständigen Fehlen eines Musters abweichen
- Wenn der Grad der Abweichung statistisch unwahrscheinlich ist, dann besteht beträchtliche Evidenz für das Vorliegen eines signifikanten Musters in den Daten
Im Fall der Entscheidungsbäume ist die Nullhypothese, daß das gerade betrachtete Attribut irrelevant ist und so der Informationsgewinn für eine unendlich große Menge Beispielen null ist. Nun muß die Wahrscheinlichkeit dafür berechnet werden, daß unter Annahme der Nullhypothese eine Beispielmenge die beobachtete Abweichung von der beobachteten Verteilung der positiven und negativen Beispiele vergleicht.
Puring liefert bei stark vertauschten Daten bessere Ergebnisse.
Welche Erweiterungen der Anwendbarkeit von Entscheidungsbäumen sind notwendig?
Es müssen Maßnahmen getroffen werden, um fehlende Daten zu ergänzen. Attribute müssen mit besonderen Eigenschaften verwendbar gemacht werden.
Fehlende Daten
Oft sind nicht alle Attributwerte für jedes Beispiel bekannt, da sie entweder nicht erfaßt oder erfaßbar sind. Dabei treten zwei Probleme treten auf:
- Wie soll man den Baum konstruieren, wenn bei einigen Beispielen die Werte fehlen?
- Wie soll ein neues Beispiel klassifiziert werden, wenn eins der Testattribute nicht anwendbar ist?
Attribute mit fehlenden Werten
Ist Zahl der Werte eines Attributes sehr hoch, kann es passieren, daß der Informationsgehalt als sehr hoch eingeschätzt wird, obwohl dies nicht der Fall ist. Solche Attribute müssen mit der Gain Ratio behandelt werden.
Attribute mit kontinuierlichen Werten
Attribute wie Größe oder Gewicht haben kontinuierliche Wertebereiche. Um sie für Entscheidungsbaum-Lernen verwendbar zu machen, müssen die Wertebereiche diskretisiert werden. Dies wird meist manuell gemacht.
Eine bessere Möglichkeit ist, die Attribute im Rahmen des Lernprozesses vorab zu untersuchen und eine sinnvolle Unterteilung des Wertebereiches zu finden.
Kapitel 8 - Neuronale Netze
Wie ist ein Gehirn aufgebaut?
Das Neuron (Nervenzelle) ist die elementare Funktionseinheit des Gehirns. Ein Neuron besteht aus einem Zellkörper (Soma), der den Zellkern enthält. An der Zelle verzweigen kurze Fasern (Dendriten) und lange Fasern (Axon). Neuronen sind über Synapsen verbunden, welche das Axon mit Dendriten oder Zellkörpern anderer Neuronen verbinden.
Wie werden Informationen im Gehirn übertragen?
Die Informationsübertragung zwischen Neuronen basiert auf einem komplizierten elektrochemischen Prozess. Wird ein elektrischer Impuls an ein Axonende übertragen, erzeugt die Synapse eine Transmittersubstanz, welcher über den Dendrit in das Neuron eindringt und dort das elektrische Potential erhöht oder erniedrigt. Falls dieses Potential einen an den Neuron gebundenen Schwellenwert erreicht, wird ein Impuls (Aktionspotential) durch das Axon geschickt, welche wieder an anderen Synapsen die Erzeugung von Transmittersubstanzen hervorrufen.
Neuronale Netze
Ein Neuronales Netz besteht aus einer Menge von Knoten (Ortsbestimmung), die durch gewichtete Kanten verbunden sind. Die Gewichte sind veränderbar. Über die Anpassung dieser Gewichte ist ein neuronales Netz lernfähig. Durch das Lernen kann das Netz seine Ausgaben, die es aufgrund bestimmter Eingaben erzeugt, ab die gewünschten Ausgaben anpassen.
Jedes Neuron (Knoten) hat Eingabekanten und Ausgabekanten, welche wieder zu anderen Knoten führen. Jeder Knoten besitzt ein Aktivierungsniveau (Schwellenwert) und ein Hilfsmittel zur Berechnung dieses Niveaus. So führt jede Einheit ihre Berechnung lokal aus. Eine globale Berechnung entfällt somit. In der Umsetzung werden aber die Berechnungen meist synchronisiert, um die Einheiten immer in einer strikten Reihenfolge abarbeiten zu können.
Was macht ein Knoten bzw. Neuron?
Hauptfunktion eines Knotens ist das Aktivierungsniveau zu berechnen und gegebenfalls die empfangenen Signale an die nächsten Einheiten weiterzuleiten. Die Berechnung erfolgt in zwei Schritten:
- Berechnung der gewichteten Summe der Eingabewerte über die Eingabefunktion (lineare Komponente)
- Berechnung des Aktivierungsniveaus über die Aktivierungsfunktion (nichtlineare Komponente)
Welche verschiedenen Aktivierungsfunktionen sind ihnen bekannt?
Für die Aktivierungsfunktion kommen eine Menge verschiedenster Funktionen in Frage. Die drei gebräuchlichsten sind die Schrittfunktion, die Signumsfunktion und die Sigmoidfunktion.
Was ist ein Bias im neuronalen Netz?
Ein Bias ist eine Erweiterung des Netzes. Ein Bias ist mit jedem Neuron verbunden, besitzt aber keine Eingabekante. Ein Bias wird verwendet, wenn keine Aktivierungsfunktion mit Schwellenwert verwendet werden soll. Statt dessen wird über diese zusätzliche Eingabe mit einem Gewicht versehen. So wird das Lernen im Netz einfacher, da nun nur noch die Gewichte geändert werden müssen und nicht mehr zusätzlich die Schwellenwerte.
Welche zwei Netzstrukturen gibt es?
Es gibt zyklenfreie (feed forward) und rekurrente Netze. Zyklenfreie Netze haben gerichtete Kanten und sind schleifenfrei. Dagegen sind in rekurrenten Netzen beliebige Strukturen erlaubt. Graphentheoretisch ist ein zyklenfreier Graph ein DAG. Die Anordnung der Neuronen wird üblicherweise in Ebenen vorgenommen. In einem geschichteten zyklenfreien Netz führen von jeder Einheit aus nur Kanten zu Einheitenn in der nächsten Ebene. Es sind keine Kanten zu Einheiten in der selben Ebene oder Kanten, die Ebenen überspingen (außer Bias) erlaubt.
Die Berechnung in rekurrenten Netzen verläuft weniger geordnet. Solche Netze können oft instabil werden und ein chaotisches Verhalten zeigen.
Wie sind die Ebenen eingeteilt?
Einheiten, welche Eingaben aus der Umwelt aufnehmen sind Eingabeeinheiten. Ihr Aktivierungswert wird durch die Umgebung bestimmt. Die Schicht, welche nur Einheiten enthält, welche Informationen an die Umgebung abgeben, sind Ausgabeeinheiten. Zwischen Eingabe- und Ausgabeeinheiten liegen die verborgenen Einheiten (hidden units). Netze welche keine verborgen Einheiten besitzen sind Perzeptrone. Solche Netze haben einen einfachen Lernprozess, haben aber eine schlechte Repräsentationsfähigkeit.
Was ist das schwierigste Problem bei Neuronalen Netzen?
Es ist extrem schwer eine optimale Netzstruktur zu finden. Ist das Netz zu klein, kann es die gewünschte Funktion nicht repräsentieren. Ist es zu groß, kann es zwar alle Beispiele der Trainingsmenge in einer Tabelle speichern, ist aber nicht Verallgemeinerungsfähig und kann neue Beispiele nicht richtig klassifizieren. (Overfitting)
Das Problem eine gute Netzstruktur zu finden, kann als Suchproblem betrachtet werden. Genetische Algorithmen sind sehr aufwendig. Ein anderes mögliches Verfahren ist das Bergsteigen, welches das Netz schrittweise modifiziert.
Quellen
Die Ausarbeitung basiert auf dem Skript von Prof. Dr. Werner Dilger